
By Yann Albou.

SoKube – silver member de la CNCF – était à la KubeCon Europe Valencia pour savourer le cru 2022, et connaître les tendances et les actualités de l’écosystème CNCF & Kubernetes. Après 2 ans de conférences virtuelles, c’était tout simplement génial d’assister à nouveau à un tel événement en personne. Les conférenciers étaient, eux aussi, ravis d’avoir de véritables interactions avec les participants.
Cet article de blog a été co-écrit par Sébastien Féré & Yann Albou
MAJ du 16/06/2022: ajout des liens des vidéos
L’événement et l’écosystème ne cessent de grandir et les chiffres ne disent pas le contraire… Près de 1200 CFP (soumissions de talk) pour 148 talks acceptés, cela ne représente donc que 12% des talks sélectionnés parmi :
Avec une telle répartition, nous comprenons mieux pourquoi nos talks SoKube n’ont pas été sélectionnés, ce qui nous donne par ailleurs des idées sur la façon de mieux partager nos expériences clients et internes!
Alors que nous passons de bons moments à Valence, nous supposons que chaque participant d’Europe (et d’ailleurs) a cependant à l’esprit la guerre en Ukraine… Le soutien à l’Ukraine était très présent lors de la session d’ouverture. Comme l’a mentionné Priyanka Sharma, la CNCF soutient le peuple ukrainien à travers Razom et l’opération Dvoretskyi. La CNCF vous invite à les rejoindre pour soutenir le peuple ukrainien et perpétuer l’esprit de la #TeamCloudNative. Visitez https://www.cncf.io/ukraine pour plus d’informations !
À propos des tendances thématiques de 2022, il y a encore quelques "tracks 101" car plus de 50% des participants sont de nouveaux venus à la KubeCon (nouveau venu ici ne signifie pas débutant cependant). Pour le reste, des sujets assez pointus, parmi :
Parmi les 148 talks, nous en avons malheureusement raté quelques-uns à cause de salles combles ou de notre fait… Nous en avons profité pour avoir des discussions fructueuses avec les sponsors sur leurs stands. En tant que société de conseil, SoKube s’associe en effet à des éditeurs dans de nombreux domaines du paysage CNCF, des distributions Kubernetes à la Sécurité, la Data, … Nous avons passé en moyenne 30min (jusqu’à 1h) sur les stands que nous avons visités, ce qui nous laisse suffisamment de temps pour approfondir les démonstrations de produits, les roadmaps, la découverte de nouveaux produits, … Ce mélange spécial de conférences et de discussions, certaines dans une ambiance décontractée le soir, est – pour nous – le mix parfait pour un événement tel que la KubeCon !
Comme Kubernetes est devenu omniprésent, la plupart – pour ne pas dire toutes – des entreprises du Fortune 500 gèrent désormais plusieurs dizaines de clusters Kubernetes, ce qui s’accompagne bien entendu de nouveaux défis… à grande échelle !
Certaines entreprises continuent d’utiliser un cluster unique, énorme, ce qui vient avec de grosses limitations pour les "Day 2 operations" (mises à niveau, ségrégation des environnements, …), en particulier si les clusters Kubernetes sont hébergés dans des datacenters privés. Cet héritage des premières années de Kubernetes est contrebalancé par des nombreux talks de la KubeCon Europe 2022 – qui visent à démontrer et à donner un retour d’expérience avec des cas d’utilisation de performance, multi-régions, multi-tenants et multi-cloud.

La conférence de Mercedes-Benz était très intéressante sur ce sujet: How to Migrate 700 Kubernetes Clusters to Cluster API with Zero Downtime – Tobias Giese & Sean Schneeweiss, Mercedes-Benz Tech Innovation
Ils exploitent et gèrent une énorme flotte de clusters Kubernetes dans le monde entier avec plus de 900 clusters (200 clusters ont été créés entre le CFP et le talk !) via 5 Platform Teams dans 4 Datacenters ! Lorsque les intervenants ont demandé dans la salle "Combien de personnes gèrent plus de 100 clusters ?", il y avait plus de monde que nous pouvions nous y attendre.
Mercedes-Benz est passé d’une infrastructure de provisionnement existante (Jenkins comme déclencheur + Terraform pour le provisionnement des clusters sur OpenStack + Ansible pour les déploiements de workloads sur Kubernetes) à l’API Cluster avec Flux & GitOps – plus d’explications sur ce qu’est l’API Cluster dans la section suivante.
Ils ont plusieurs clusters de gestion qui prennent en charge jusqu’à 200 clusters Kubernetes en aval avec un objectif de zéro temps d’indisponibilité, en utilisant ce workflow de migration : Datacenter Infrastructure, Worker nodes, Control plane.
Cette conférence démontre une migration à grande échelle de Kubernetes avec plusieurs retours d’expériences :
Avant d’augmenter le nombre de nœuds, vous souhaiterez peut-être optimiser l’utilisation des ressources de votre cluster. Vertical Pod Autoscaler (VPA) est une fonctionnalité mal connue qui pourrait aider dans cette situation et qui est très bien décrite dans le talk de Vincent Sevel – How Lombard Odier Deployed VPA to Increase Resource Usage Efficiency – Vincent Sevel, Lombard Odier – il s’agit d’un véritable retour d’expérience où les contraintes de demande et de limites pour la CPU ou la mémoire sont décrites et où l’approche VPA est expliquée pour améliorer et optimiser l’utilisation de ces ressources. VPA est une ressource CRD (Custom Resource Definition) qui ajuste les ressources de type Request et Limits en fonction de métriques.
Ainsi, au lieu de coder en dur les valeurs dans votre déploiement YAML (ou toute autre ressource Kubernetes), VPA trouvera la bonne valeur basée sur les percentiles 90 (P90) en utilisant les métriques internes ou celles de Prometheus.
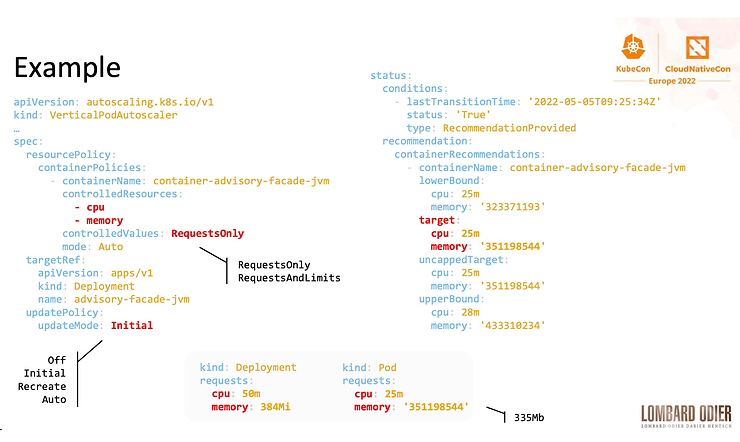
Quelques éléments d’attention: la faible recommandation CPU faite par VPA, avoir 1 objet VPA par Déploiement, les spécificités JVM et autres…
Dans son talk Autoscaling Kubernetes Deployments: A (Mostly) Practical Guide – Natalie Serrino, New Relic (Pixie team), Natalie Serrino décrit les 3 options de mise à l’échelle d’un cluster Kubernetes – Cluster Autoscaler, Vertical and Horizontal Pod Autoscaler – passant la plupart du temps sur son préféré.

L’Horizontal Pod Autoscaler a en effet des options très utiles pour les scénarios de la vie courante (ne pas adapter trop rapidement la charge aux stimuli externes, augmenter ou diminuer en douceur, …) et peut être utilisé avec des métriques définies par l’utilisateur:
Pour le moment, vous ne pouvez pas utiliser en même temps HPA et VPA sur les mêmes métriques (ex : CPU), mais les contributeurs travaillent sur un tel scénario !
Comme souvent lorsque les use-cases deviennent monnaie courante dans le paysage CNCF, la standardisation apparaît. La gestion de cluster suit également cette règle avec la Cluster API.

La Cluster API est un nouveau standard du SIG Kubernetes qui permet de créer et de gérer une flotte de clusters Kubernetes à l’aide d’une API standard soit on premise, soit dans une infrastructure cloud (gérée ou non). voir kubernetes-sigs/cluster-api & Introduction – The Cluster API Book
Quelques talks sympas sur cette API lors du Kubecon :
L’objectif est de se concentrer sur les 80% de gestion du cluster et de rendre le reste possible. Voici le cluster Management qui exploite l’API CRD de Kubernetes :
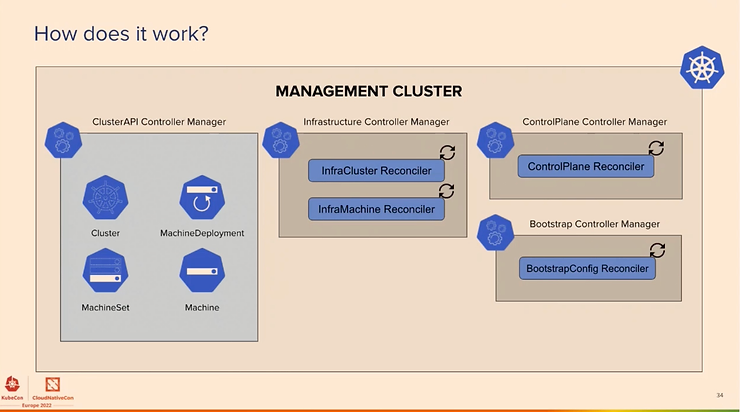
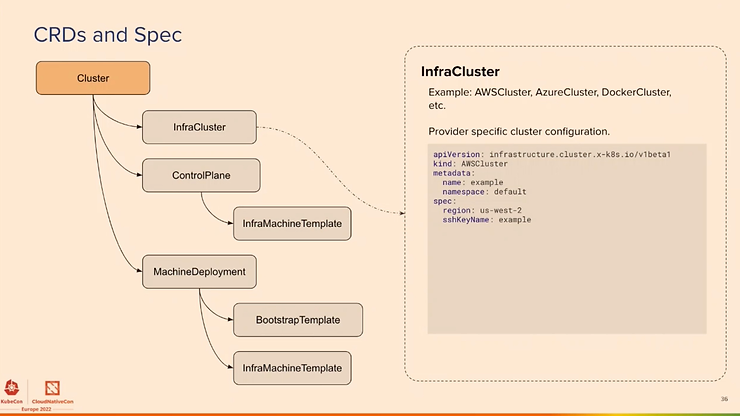
Les nouvelles fonctionnalités concernent ClusterClass et Managed Topologies, Ignition et Flatcar support, clusterctl pour Windows et le support d’ARM, plus de fournisseurs (IBM Cloud, Bring your Own Host, Oracle Cloud, Nutanix, …). La liste des implémentations pour les fournisseurs se trouve ici.
Dans les fonctionnalités à venir : intégration de niveau supérieur du système d’exploitation et de l’amorçage des nœuds, amélioration de la partie bare metal et edge, mise à l’échelle automatique depuis et vers 0, rotation des certificats, …
Cette API est production-ready depuis la version 1.0 en octobre 2021, et de nombreuses entreprises l’utilisent déjà en production : Twilio, Giant Swarm, Spectro Cloud, Talos Systems, New Relic, RedHat (l’API Machine vient de RedHat), Deutsche Telecom, US Army , Microsoft Azure, Amazon AWS EKS, D2iQ, Samsung SDS, SK Telecom, Mercedes Benz, VMWare,
Nous vous encourageons vraiment à jeter un coup d’œil sur cette Cluster API qui continuera de prendre de l’importance…
Certainement un sujet prépondérant pour cette édition, qui laisse envisager que la sécurité est une préoccupation très importante tant au niveau de l’infrastructure que de la chaîne d’approvisionnement logicielle.
D’après les discussions avec les fournisseurs, également attesté par nos retours sur le terrain, il semble que les utilisateurs finaux aient une faible maturité en matière de sécurité – nous supposons qu’un tel écart provient de l’usage toujours très répandus d’anciens paradigmes tels que la défense périmétrique).
La CI/CD a rarement été au centre des préoccupations en matière de sécurité, mais en raison du "Shift Left" et des approches "Zero Trust", cela devient un réel point d’attention. Les attaques de la chaîne d’approvisionnement se multiplient à un rythme rapide ! Certains produits de sécurité commencent à se focaliser sur cette préoccupation en proposant une approche holistique de la sécurité.
Une présentation amusante mais très intéressante sur la façon de sécuriser votre chaîne d’approvisionnement :
Make the Secure Kubernetes Supply Chain Work for You – Adolfo García Veytia, Chainguard
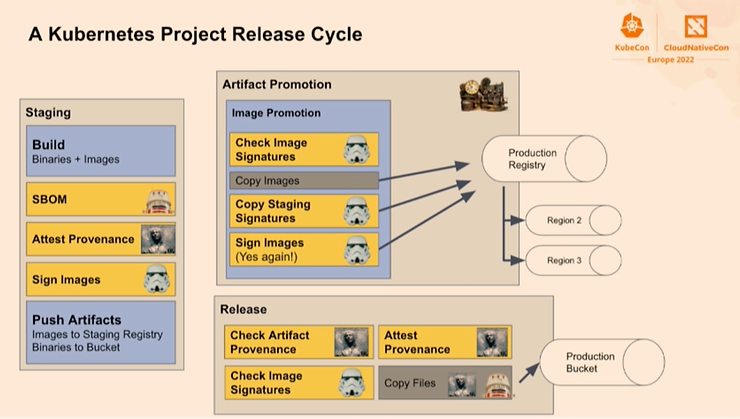
Il parle de la gestion des versions décrivant un cycle de publication de projet Kubernetes (en s’appuyant sur kubernetes/sig-release) en utilisant des concepts comme SBOM, Attest Provenance, Signing, Build Promotion, Registry dédiée (et même par régions), Provenance verification, … A voir absolument!
Cilium, créé par Isovalent, est en passe de devenir l’implémentation CNI par défaut car il est maintenant utilisé comme couche de réseau et sécurité dans Google GKE et Amazon EKS.
Cilium: Welcome, Vision and Updates – Thomas Graf & Liz Rice, Isovalent; Laurent Bernaille, Datadog
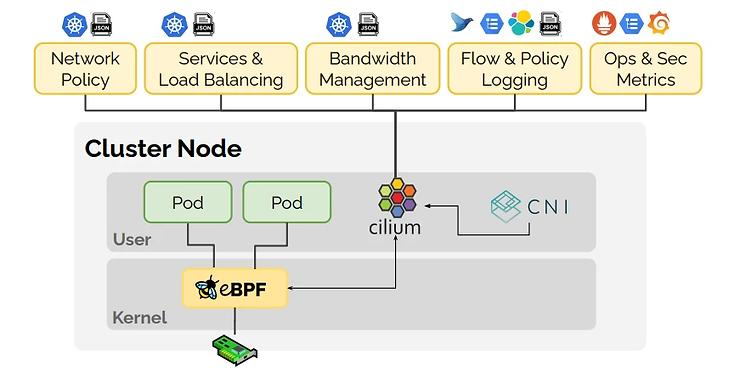
Quand Isovalent annonce de nouveaux produits à la KubeCon, il faut y prêter attention !

Découvrez également l’excellente présentation de Liz Rice sur Cilium Service Mesh qui explique ce qu’est un Service Mesh et l’architecture Cilium avec une approche sans sidecar en déplaçant l’implémentation du Service Mesh vers le noyau via eBPF (suppression de la nécessité, dans certaines situations, d’utiliser un chemin réseau L7) et améliorant ainsi les performances.
Comme tout autre domaine du paysage CNCF, la maturité vient avec la normalisation – voici donc la spécification et le statut d’OpenTelemetry ! OpenTelemetry est actuellement le deuxième projet CNCF le plus actif, derrière Kubernetes…
OpenTelemetry: The Vision, Reality, and How to Get Started – Dotan Horovits, Logz.io
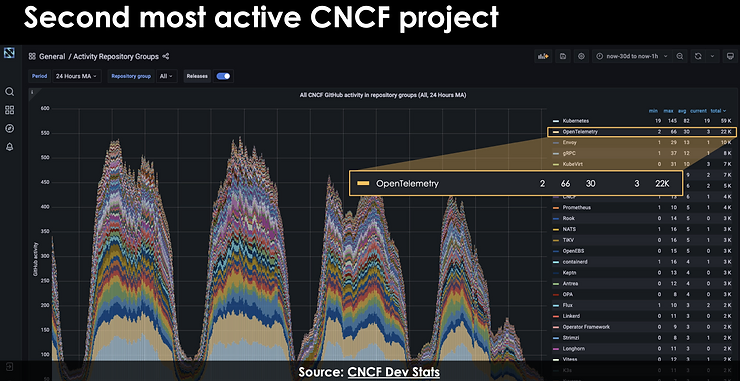
OpenTelemetry (alias OTel) est un framework d’observabilité – des logiciels et des outils qui aident à générer et à capturer des données de télémétrie à partir de logiciels cloud-natifs – en utilisant les 3 piliers que sont les Traces, Metrics, et Logs.
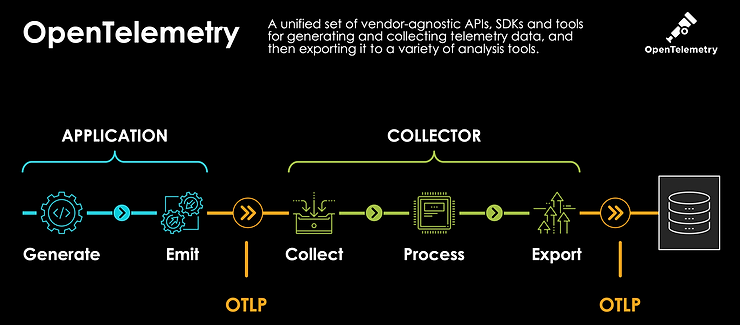
Étonnamment, le sujet le plus avancé est actuellement la partie Tracing. Le sujet Metrics devrait être Stable / GA dans quelques semaines car la Release Candidate a été publiée juste avant la KubeCon.

Il y a eu plusieurs présentations dédiées à GitOps, mais beaucoup d’autres présentations incluaient indirectement l’approche GitOps – non seulement pour les déploiements d’applications mais aussi pour les déploiements d’infrastructures !
Tout comme Kubernetes est devenu la norme pour l’orchestration de conteneurs il y a quelques années, GitOps est devenu la norme de facto pour déployer des workloads sur des clusters Kubernetes avec en particulier les deux produits phares ArgoCD et Flux.
Nous ne décrirons pas en détail mais beaucoup de belles choses à venir avec Argo et Flux. Voici quelques-unes de ces présentations:
La dernière avec Skyscanner était vraiment intéressant et montre comment une erreur dans un repo GitOps avec Helm et ArgoCD peut conduire à une situation très périlleuse avec une suppression massive de tous les services (478) dans tous les namespaces à travers toutes les AZ et régions ! Juste avec cette "petite" modification :

Un vrai cauchemar "GitOops" comme on les aime ! Suite à cet incident, des mesures ont bien sûr été prises, une priorisation par région fonctionnelle et un scheduling des applications non-critiques en premier…
Une bonne étude de cas sur le chaos engineering: Case Study: Bringing Chaos Engineering to the Cloud Native Developers – Uma Mukkara, ChaosNative & Ramiro Berrelleza, Okteto
Cet talk explique clairement ce qu’est le chaos engineering et pourquoi l’utiliser. Le Chaos Engineering fait partie de la culture DevOps non seulement pour votre environnement de test ou de prod mais aussi pour l’équipe de développement avec différents niveaux de maturité (Chaos Engineering Maturity level).
L’étude de cas mélange un cas d’utilisation intéressant entre Litmus (une plate-forme Chaos Engineering) et Okteto (un outil qui permet à l’équipe de lancer rapidement des environnements de développement basés sur Kubernetes) pour exécuter des expériences de Chaos Engineering de manière continue dans un processus de développement.
Quand il s’agit de comprendre une facture Cloud pour un Financier, cela peut être assez rebutant… Des dizaines de lignes dans un tableur sans aucune possibilité de facturer une ligne Business ou une autre.
Ce sujet n’est pas nouveau, mais il bénéficie d’une nouvelle visibilité grâce à Kubernetes et à la CNCF. Il y a des années, le producteur de coûts et le gestionnaire de coûts étaient les mêmes entités dans une organisation. Aujourd’hui, tous les ingénieurs produisent des coûts – ce qui est un changement radical !
FinOps is an evolving Cloud Financial Management discipline and cultural practise, cela – tout comme DevOps l’a fait – aide à briser les silos et à augmenter la valeur commerciale. Il permet également des décisions sur les dépenses, principalement en assurant la transparence et le contrôle des coûts, ce qui passe par :
La Finance doit absolument travailler main dans la main avec les ingénieurs afin de gérer correctement et efficacement les coûts sur les plates-formes natives du cloud – vous en entendrez parler bientôt, c’est sûr !
C’était une nouvelle KubeCon incroyable ! Nous vous encourageons fortement, si vous n’êtes pas familier avec ces sujets, à jeter un œil à ces différents thèmes, produits et tendances.
Malheureusement, cet article de blog ne peut pas couvrir de manière exhaustive toutes les sessions et toutes les discussions très intéressantes avec des personnes, des conférenciers, des sponsors, des fournisseurs sur les retours d’expériences, les actualités, les fonctionnalités, les produits, …
Si vous souhaitez obtenir plus d’informations ou des explications plus approfondies sur des sujets spécifiques, contactez-nous.
Et si vous étiez à la conférence, n’hésitez pas à partager vos sessions préférées ou vos remarques dans les commentaires.
Découvrez toutes les vidéos qui sont maintenant disponibles publiquement sur la chaîne YouTube de la CNCF et réservez déjà votre agenda pour les prochaines Kubecon :