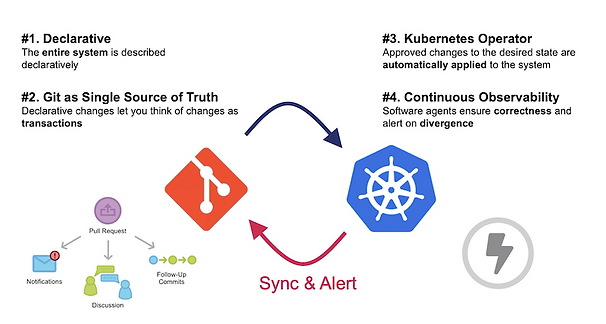
GitOps est maintenant une approche bien connue pour la livraison de votre logiciel, mais elle ne fournit ni un cadre pour représenter les différents environnements cibles ni une solution pour propager les changements d’une étape à l’autre.
Alors quelles sont les solutions pour décrire nos environnements Dev, QA ou Production et surtout comment propager les changements d’un environnement à l’autre de manière efficace, automatisée et sécurisée ? Une vidéo faite durant les DevOps D-Day sur ce sujet est disponible: GitOps & the deployment branching model – Yann Albou – DEVOPS D-DAY #6
GitOps intro
Nous avons déjà couvert les concepts de GitOps dans un article de blog précédent, donc si vous n’êtes pas déjà familier avec GitOps, cela pourrait être un bon moyen de commencer avec GitOps avant: GitOps and the Millefeuille dilemma Vous trouverez ci-dessous un résumé rapide des principes de GitOps :
Tout doit être défini dans un référentiel Git (selon que vous êtes un puriste GitOps ou non, il peut y avoir quelques exceptions telles que les informations d’identification stockées dans un coffre externe comme Vault)
Ne stockez pas les configurations dans des variables d’environnement de votre outil de CI ou de CD
Vous devez promouvoir les artefacts, pas le code source
Respecter les principes d’idempotence et d’immuabilité (qui englobe également les dépendances externes et les services)
Pas de solution unique qui couvre tous les besoins
Depuis sa création en 2017 par Weaveworks, la plupart des livres sur le sujet GitOps décrivent extrêmement bien les concepts derrière, mais restent flous sur la plupart des aspects pratiques :
Comment gérer les ressources dynamiques (Autoscaling, Canary Deployment, …) ?
Comment réaliser des tests avec un déploiement réel dans le CI ?
Quelles sont les bonnes pratiques de rollback (revert, commit rollback,…) ?
Comment rendre l’observabilité à un niveau supérieur ? Le déploiement continu peut-il se produire naturellement dans GitOps (automatisation des PR requise) ?
Comment gérer les secrets dans Git ?
GitOps reste un ensemble de principes, et comme nous l’avons vu, beaucoup de détails restent à régler pour les DevOps… Dans cet article de blog, nous nous concentrerons sur deux aspects uniquement : la représentation de l’environnement cible et la promotion de versions.
GitOps ne fournit ni un framework pour représenter les différents environnements ni une solution pour propager les changements d’une étape à l’autre.
Environnement cible
Avec GitOps la représentation de l’environnement cible sur lequel déployer les applications est généralement : Dev, Int, QA, Prod.
Mais comment GitOps peut-il nous aider à gérer les changements de ces environnements ?
Branching Model pour les environnements cibles
Je considère comme une bonne pratique l’utilisation des référentiels git séparés entre le code source de l’application et le code de description de déploiement de l’application/du système (yaml, Helm, kustomize, etc.), pour diverses bonnes raisons :
Il s’agit de 2 cycles de vie différents en termes de mise à jour, de version et de publication : les changements dans l’un n’impliquent pas nécessairement des changements dans l’autre
Les aspects de sécurité avec RBAC s’appliquent différemment
Les pipelines CI/CD pour le code source et pour le manifest de déploiement de l’application sont vraiment différents, bien que leur structure puisse être similaire par essence (pre-flight, qualité, contrôles de sécurité, validation, tests, post-flight).
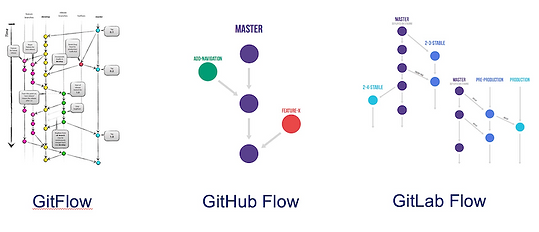
Les modèles de branchement sont différents : pour un référentiel de code source, nous considérerons les modèles GitFlow (ou pas!), Git Simple Flow, Github flow, GitLab Flow, … en fonction des besoins en termes de branches de publication, de branches de support, d’un mode de développement « trunk based development », de versions multiples et de multi-tenant en production. Du côté du dépôt de déploiement, les besoins sont différents et liés à la gestion de la configuration dans chaque environnement cible.
Lorsque vous utilisez plusieurs applications, vous pouvez avoir besoin d’une configuration système/application générique qui ne peut pas être stockée dans un seul référentiel d’applications Git (par exemple, lors de la publication de plusieurs micro-services ensemble)
Mélanger les journaux Git (Git Logs) correspondant aux commits d’application avec les modifications de déploiement est une mauvaise idée qui pourrait entraîner le masquage de l’historique du déploiement.
L’objectif de ce blog n’est donc pas de décrire le branching model git pour gérer le code source mais de se concentrer sur le branching model de déploiement de votre application ou de votre produit.
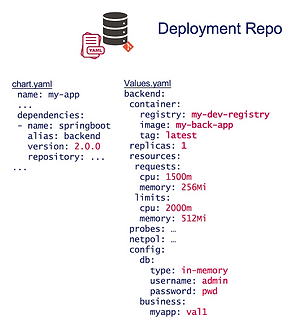
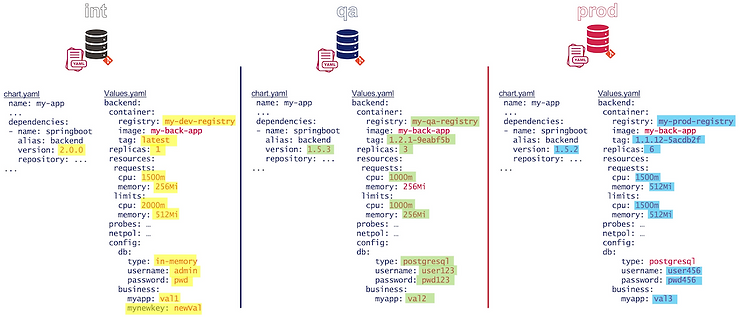
En supposant le déploiement d’un backend Springboot dans un cluster Kubernetes, la configuration peut ressembler à celle ci-dessous :
Quelles sont les options possibles pour représenter ces types de manifests de deploiements dans les différents environnements cibles ?
1 environnement par dépôt Git
1 environnement par branche
1 environnement par répertoire ou fichier
Décrivons chacune de ces options, les avantages et les inconvénients
1 environnement par dépôt Git
L’approche à un dépôt par environnement/cluster (au passage approche recommandée par Jenkins X) est illustrée ci-dessous :
Avantages:
Forte isolation : en termes de configuration, de sécurité et d’autorisations, cette solution fournit une forte isolation afin que nous puissions avoir différents groupes d’utilisateurs et d’administrateurs utilisant des commandes git de base sans s’appuyer sur les branches, les merges et l’utilisation de plugins externes.
Les inconvénients:
Administration : chaque référentiel Git (c’est-à-dire l’environnement cible) doit être configuré et administré, ce qui signifie du temps et de la gestion (Configuration, paramètres de sécurité, sauvegarde, …), bien qu’il puisse être automatisé.
Pull Request : vous ne pouvez soumettre des PR qu’entre des référentiels qui ont été dérivés les uns des autres (même ancêtre). La promotion ne sera pas trop difficile tant que les différences entre l’environnement précédent ne divergent pas trop. Sinon, les conflits seront récurrents.
tous les autres inconvénients de la solution suivante
Je ne détaillerai pas plus cette solution car elle présente trop d’inconvénients par rapport aux solutions suivantes.
1 environnement par branche
Au lieu de s’appuyer sur des référentiels git, une manière courante de représenter l’environnement kubernetes cible consiste à mapper chaque environnement cible sur une branche spécifique à l’intérieur d’un seul référentiel Git :
Avantages:
Une structure de système de fichiers simple qui représente un ensemble unique de ressources
Un cluster est modifié en modifiant sa branche
Les branches divergentes ou les clusters/environnements divergents peuvent être facilement détectés via git diff
Le RBAC par branche est facile à configurer afin que vous puissiez avoir une équipe dédiée avec des privilèges plus élevés sur une branche spécifique. Typiquement il est possible de configurer certaines options comme « Allow to merge », « Allow to push » pour un groupe spécifique, … Ces règles de protection de branche sont des fonctionnalités spécifiques à un outil et varient d’un fournisseur à l’autre (GitLab, Github, Bitbucket, . ..).
La figure ci-dessous met en évidence les différences entre les branches et les environnements :
Les inconvénients:
Le processus de Pull Request est compliqué car il faut choisir la bonne branche comme base de comparaison/cible de merge : l’ordre de promotion, Dev à QA à Prod, n’est pas géré par Git.
Certaines modifications devront être fusionnées dans toutes les branches : cela nécessite un effort supplémentaire pour maintenir toutes les branches synchronisées (en cas de correctifs ou de modifications de configuration).
Des branches divergentes peuvent potentiellement provoquer des conflits de merge : cela ouvre la porte aux utilisateurs pour effectuer des commits sur des branches spécifiques et inclure du code spécifique à l’environnement.
La conséquence des 2 points précédents est qu’il faut respecter le flux de propagation des changements (ex : Dev -> test -> prod) pour éviter ces problèmes de fusion et de conflit… Ce qui rend difficile le cas d’utilisation du patch direct en Prod (par exemple, lorsque l’environnement de test est gelé).
La promotion d’un nouvel élément structurel est plus difficile avec un modèle de branchement : que vous utilisiez helm ou tout autre framework de template, la nécessité d’ajouter de nouveaux éléments dans votre template (nouveau paramètre, supprimer la configuration, …) est classique.
La question est de savoir comment favoriser ce changement dans tous les environnements ? Avec une approche par branche, il est plus difficile de trouver un mécanisme ou de demander aux gens de le faire. Soit il y aura un oubli soit une mauvaise config
Pas une solution de mise à l’échelle : dans cet exemple, seuls 3 environnements sont décrits, mais les choses deviennent plus complexes à mesure que les environnements augmentent.
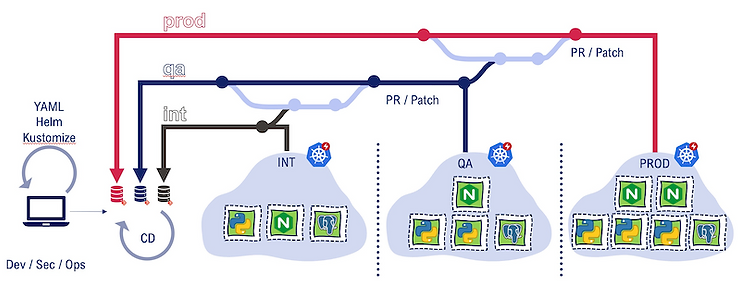
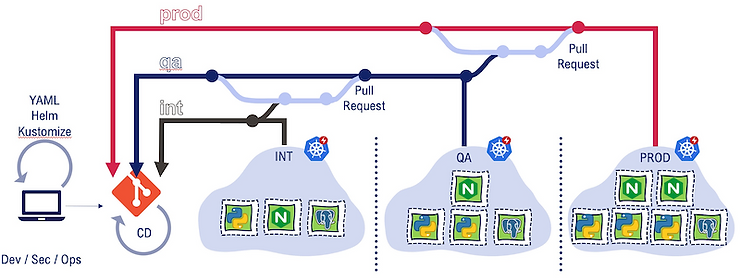
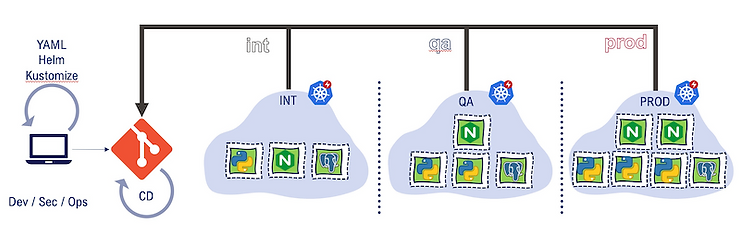
1 environnement par répertoire ou fichier
Une autre solution consiste à avoir un référentiel Git utilisant uniquement la branche principale.
Et à l’intérieur de cette branche principale, avoir un répertoire ou un fichier par environnement (par exemple, un fichier yaml complet contenant toutes les spécificités de l’environnement, comme un fichier helm value.yaml).
Promouvoir via git est toujours quelque chose qui peut être compliqué si le pourcentage des différences entre les environnements est important. Et c’est courant dans des situations réelles.
Cette solution est un moyen d’éviter ce casse-tête de promotion !
Avantages
Structure de branche plus simple : une seule branche signifie aucun risque de conflits de merge
Un cluster est modifié en modifiant son répertoire (ajout/suppression)
Le processus de Pull Request est simple : branchez le maître, fusionnez avec le maître
Les mises à jour multi-cluster sont plus simples : comparaison côte à côte de l’état du cluster dans le référentiel, copier-coller les modifications entre les fichiers
Possibilité de factoriser entre les environnements pour les paramètres communs ou les paramètres par défaut
La promotion d’un nouvel élément structurel est plus facile : la promotion d’un nouveau changement structurel (comme un nouveau paramètre obligatoire pour votre application) est plus facile à organiser au sein d’une branche unique. Lorsqu’une/un Dev ou une/un Ops ajoute un paramètre, il/elle est responsable de la cohérence dans tous les environnements.
Dans cette situation, toutes les clés ne sont pas nécessairement valorisées par le/la développeur(se)
Un processus de cohérence automatique doit être mis en place par le biais d’un processus de vérification préalable au vol dans le CD.
Possibilité de basculer d’un env à un autre : flux pas forcément linéaire : DEV / INT / QA / PP / PRD. Mais le correctif n’est pas forcément sur tous les env (merge pb dans d’autres solutions)
Duplication d’env simplifiée : créer ou dupliquer un nouvel env à partir d’un autre est plus facile : pas de manipulation de git ou de branche. De plus, des outils comme ArgoCD ou Flux permettent de gérer facilement ce genre de situation.
Les inconvénients
Les environnements divergents peuvent être plus difficiles à détecter (ne peut pas compter sur les outils git par défaut pour par exemple la comparaison des différences)
Le RBAC n’est pas directement possible, il faut s’appuyer sur une solution spécifique pour appliquer des permissions différentes entre le répertoire dev et votre répertoire prod (Codeowner est un plugin bien connu pour répondre à ce besoin qui existe sur GitLab, Github, Bitbucket, … )
Les paramètres communs sont les mêmes pour tous les envs, donc le risque d’appliquer une fonctionnalité ou un patch involontaire en production est donc plus élevé et pourrait casser votre prod !
Pour éviter cette situation, des modifications rétrocompatibles sont conseillées.
Un inconvénient « bureaucratique » pourrait être une façon de travailler beaucoup plus éloignée d’un mode ITIL, dans lequel l’isolement des opérations par branches est plus naturel pour la matrice RACI ou le contrôle strict des modifications. Mais ici on rentre vraiment dans les principes DevOps !
Approche Mixte
Bien qu’avoir des paramètres communs soit à la fois plus cohérent et plus facile en termes d’opérations, cela ajoute également un certain risque dans certaines situations et demander une rétrocompatibilité n’est pas aussi simple qu’il y paraît (notamment en termes de test).
Pour résoudre ce genre de problème, rien ne nous empêche d’avoir une approche mixte entre ce « 1 env par répertoire ou fichier » et un pipeline Git flow spécifique avec quelques principes issus des pipelines Git Flow existants (mais pas tout afin de s’adapter à ce besoin particulier).
Cela signifie qu’une branche principale contenant 1 répertoire ou fichier par environnement existe toujours (comme dans la solution précédente) et que d’autres branches (hotfix, release branch, …) pourraient également exister pour couvrir certaines situations plus complexes.
Cela pourrait être l’option la plus pertinente pour traiter les cas d’utilisation les plus compliqués comme le hotfix, la Release branch, plusieurs versions de nos logiciels en production, l’approche produit, …
Par exemple, le Hotfix en production est un cas d’utilisation courant mais pas facile à réaliser en fonction du contexte. Pour tester un correctif avant de l’appliquer en production, existe-t-il un environnement de pré-prod ? Ou pouvons-nous créer des environnements à la volée ? Et si oui, comment le patch y est-il appliqué ?
Avoir un pipeline Git Flow où la branche principale représente la production et une branche de Hotfix (où le correctif est validé) aidera certainement sur ces aspects !
Ces approches ne sont donc pas mutuellement exclusives, au contraire, elles sont complémentaires voire obligatoires pour certaines situations.
Ce qui est intéressant, c’est de pouvoir commencer simplement avec une approche « 1 env par répertoire ou fichier » et d’ajouter de la complexité si nécessaire. Et ce choix peut se faire par référentiel Git, il n’est pas nécessaire d’avoir une approche globale pour toute l’entreprise.
Il faudrait décrire plus en profondeur cette partie qui demande beaucoup plus d’explications dans la mise en place et le fonctionnement (Prochain blog…).
Tooling ?
Plusieurs outils peuvent nous aider à composer et appliquer un modèle GitOps fonctionnel : comme : Argo, Flux, Helm, Kustomize, …
ArgoCD et Flux sont les outils en charge de la correspondance entre la représentation de l’environnement dans Git et les déploiements réels. Ils prennent en charge toutes les approches décrites ici et ajoutent également des fonctionnalités vraiment intéressantes comme la possibilité de créer dynamiquement un env de manière générique (c’est-à-dire que l’ajout d’un répertoire ou d’une branche sera automatiquement découvert et le déploiement commencera…)
À titre d’exemple, jetez un œil à ce repo qui combine ArgoCD + Kustomize + Helm pour la solution « 1 env par répertoire ou fichier »:
« New users to GitOps and Argo CD are not often sure how they should structure their repos, add applications, promote apps across environments, and manage the Argo CD installation itself using GitOps. »
« The GitOps Application Manager command-line interface (CLI), kam, simplifies GitOps adoption by bootstrapping Git repositories with opinionated layouts for continuous delivery. It also configures Argo CD to sync configurations across multiple Red Hat OpenShift and Kubernetes environments »
« automate the continuous delivery of change through your environments via GitOps and create previews on Pull Requests to help you accelerate«
Plus que de simples outils GitOps: Kubernetes platform, Tekton pipelines for CI/CD, PR and ChatOps system (jenkins-x/lighthouse)…
Ne sera pas « production ready »
Ces solutions sont pratiques pour démarrer facilement et fournir un modèle GitOps fonctionnel, mais elles nécessitent un strict respect de leur modèle sous-jacent, et une personnalisation vers un modèle divergent s’avérera soit impossible, soit difficile.
Dans tous les cas, il est important de comprendre le fonctionnement de ces solutions et de valider si elles s’intègrent bien dans votre modèle de déploiement.
Autres considérations importantes
Multi-app Repo et Produit
Un autre sujet lié aux approches décrites précédemment est quelle est la portée du référentiel ? Doit-on avoir un référentiel par composant (un backend, un microservice, un frontend,…) ou faut-il regrouper tous les composants dans un seul référentiel ?
Voici quelques possibilités quand on parle d’agrégation de ces dépôts :
Mono-repo : un seul repo avec toutes vos applications à l’intérieur pour que vous ayez une vue globale avec un versionning global. Cela nécessite une bonne organisation et complique le RBAC.
Dépôt par équipe : Toutes les applications, tous les services gérés par une équipe se trouvent dans un seul dépôt. Il donne une plus grande autonomie à l’équipe dédiée.
Repo par Produit/Service/Application : Il s’agit d’une solution fine qui donne plus de contrôle sur la précédente en mettant l’accent sur l’approche produit.
Nous ne couvrirons pas ces aspects ici (probablement dans un autre article de blog).
Multi-tenancy
Le plus souvent, il n’y a qu’une seule instance de l’application en production, ce qui se traduit par un petit nombre d’environnements cibles (Dev, Int, QA, Prod, etc.)
Mais dans certaines situations, l’application doit être déployée autant de fois qu’il y a de tenants. Par exemple, un tenant peut être un pays (un client, une équipe, …) et la même application (binaire, conteneur) doit être déployée pour chaque pays mais avec une configuration différente.
La même question s’applique ici sur la façon de représenter les tenants pour gérer les déploiements.
Et les mêmes solutions pourraient être proposées mais avec quelques spécificités :
La factorisation est plus importante dans cette situation car il y a probablement des paramètres communs à regrouper pour l’ensemble des tenants ou un sous-ensemble.
La sécurité et l’isolement entre les tenants peuvent être très importants et cela affecte la gestion des référentiels ou des branches.
Le RBAC pourrait être plus compliqué à gérer en cas de RBAC dédié par tenant et par environnement.
La promotion du changement n’est plus un processus linéaire (Dev à Int à QA à Prod). Avec une approche multi-tenant, nous pouvons déployer une version spécifique d’un tenant en Dev, test ou prod et le reste des tenants avec d’autres versions.
L’utilisation d’un pipeline GitFlow est appropriée pour gérer des situations plus compliquées
Environnements à la volée
La possibilité de créer des environnements à la volée pourrait changer la donne dans ce qui est décrit ici !
Si une application est facile à déployer (peu de dépendances, faible consommation de ressources/données), le processus de test est grandement simplifié.
De plus, chaque fonctionnalité peut être facilement testée de manière isolée, ce qui permet de passer à l’étape suivante : le « Progressive Delivery ».
Fournir un ensemble de fonctionnalités à un environnement cible nécessitait l’utilisation d’un environnement par fichier/répertoire/branche. Avec la livraison progressive, les fonctionnalités en production sont introduites avec les « feature flags » sur une seule branche (trunk-based development).
C’est un sujet plus avancé qui demande de la maturité sur les processus de développement et de livraison.
Conclusion
On ne peut qu’apprécier les avantages de GitOps en termes de productivité, d’expérience développeur, de stabilité, de fiabilité, d’audit et de sécurité. Mais GitOps reste une philosophie/méthode/ensemble de principes, et comme le diable est toujours dans les détails, les équipes doivent trouver comment représenter leurs environnements dans leurs référentiels et comment promouvoir les releases.
GitOps est principalement une question de gestion de configuration, de modèle de branchement Git et de Git RBAC.
Certains critères aideront les équipes à choisir l’approche la plus appropriée pour leurs cas d’utilisation :
Cycle de vie de l’application – Influence la conception du branching model git.
Gestion de la configuration – Comment le code de déploiement/gestion de l’application est-il organisé et modifié.
Niveau de complexité de vos déploiements
Besoin de factorisation
Isolement / ségrégation / RBAC
Processus intégré ou ad hoc
Niveau de maîtrise de Git au sein de l’équipe (ne devrait pas être un critère…)
Comme d’habitude dans l’univers du déploiement, il n’y a pas de « solution unique » pour tous les cas d’utilisation. Cela dépend vraiment du processus, de l’organisation, du niveau de sécurité, du type de produit, si la solution est développée en interne ou uniquement intégrée, … Même au sein d’une entreprise, plusieurs approches peuvent coexister en fonction des différents besoins.
Aussi certains que les outils peuvent aider, ils ne devraient pas être la première préoccupation lors de la mise en œuvre d’une stratégie GitOps : chez Sokube, nous pensons qu’une automatisation appropriée, la recherche de simplicité et de sécurité sont toujours de meilleurs principes que des solutions fortement personnalisées et difficiles à maintenir.
Pour offrir les meilleures expériences, nous utilisons des technologies telles que les cookies pour stocker et/ou accéder aux informations des appareils. Le fait de consentir à ces technologies nous permettra de traiter des données telles que le comportement de navigation ou les ID uniques sur ce site. Le fait de ne pas consentir ou de retirer son consentement peut avoir un effet négatif sur certaines caractéristiques et fonctions.
Fonctionnel
Toujours activé
Le stockage ou l’accès technique est strictement nécessaire dans la finalité d’intérêt légitime de permettre l’utilisation d’un service spécifique explicitement demandé par l’abonné ou l’utilisateur, ou dans le seul but d’effectuer la transmission d’une communication sur un réseau de communications électroniques.
Préférences
Le stockage ou l’accès technique est nécessaire dans la finalité d’intérêt légitime de stocker des préférences qui ne sont pas demandées par l’abonné ou l’utilisateur.
Statistiques
Le stockage ou l’accès technique qui est utilisé exclusivement à des fins statistiques.Le stockage ou l’accès technique qui est utilisé exclusivement dans des finalités statistiques anonymes. En l’absence d’une assignation à comparaître, d’une conformité volontaire de la part de votre fournisseur d’accès à internet ou d’enregistrements supplémentaires provenant d’une tierce partie, les informations stockées ou extraites à cette seule fin ne peuvent généralement pas être utilisées pour vous identifier.
Marketing
Le stockage ou l’accès technique est nécessaire pour créer des profils d’utilisateurs afin d’envoyer des publicités, ou pour suivre l’utilisateur sur un site web ou sur plusieurs sites web ayant des finalités marketing similaires.