
By Vincent Zurczak.
Ce billet inaugure une collection d’articles autour de la thématique « travailler avec plusieurs clusters Kubernetes ». Cette série donne ainsi l’opportunité à l’équipe SoKube de partager des retours d’expérience et d’explorer différents aspects, de la conception à l’exploitation, en passant par les angles financiers et organisationnels.
Mais avant toute chose, il serait sans doute bénéfique de rappeler quand cette problématique se pose. Il existe deux grandes catégories de besoins qui poussent une organisation à mettre en place plusieurs clusters :
Détaillons donc tout cela.
Comme son nom l’indique, cette catégorie a trait à la mise en place d’infrastructures robustes, avec la tolérance aux pannes comme première préoccupation. Elle se décline en 3 cas d’usages.
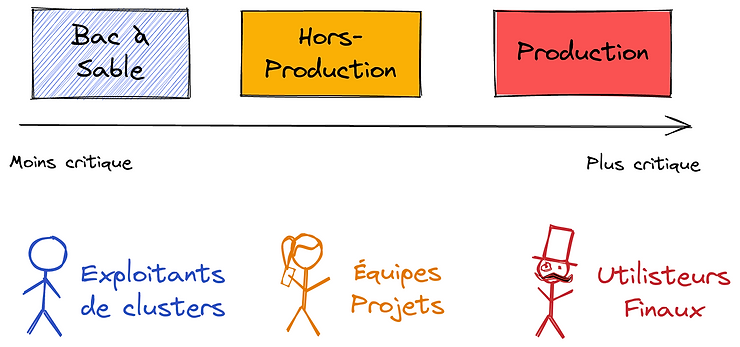
La situation la plus fréquente est d’avoir un cluster par environnement, ou par type d’environnement. Le nombre de clusters / environnements peut aller au-delà selon les organisations, mais il en faut 3 a minima :
Il est essentiel de comprendre que 3 clusters / grappes est un minimum, chacun adressant des préoccupations et des SLA différents.
L’intérêt d’avoir plusieurs clusters réside dans l’isolation (la production ne devrait jamais être impactée par les autres environnements) et l’efficacité de la maintenance. Ainsi, les mises à jour et évolutions sont d’abord testées sur le bac à sable. Une fois rodées, elles peuvent être appliquées sur le cluster hors-production. Et une fois l’impact connu sur les applications, elles peuvent être jouées en production. Cette progressivité, de la grappe la moins critique à la plus sensible, atténue le risque de drames en production. Cela améliore également la confiance des équipes dans leurs procédures, en particulier pour des personnes arrivées récemment. Enfin, cette ségrégation traduit un équilibre entre mutualisation des ressources (il est possible de regrouper des environnements dans un même cluster – hors-production) et clarté quant à la gouvernance (chaque grappe ayant ses préoccupations et un SLA bien identifiés).
Un deuxième cas d’usage assez fréquent concerne le changement de fournisseur ou d’éditeur pour sa solution Kubernetes. Par exemple, migrer d’OpenShift 3.x vers Rancher. Ou même d’OpenShift 3.x vers OpenShift 4.x – puisqu’il n’existe pas de mécanique automatisée entre les 2 versions majeures. Ou bien encore basculer d’une version hébergée en interne vers une solution cloud comme GKE, EKS, AKS…
La stratégie la plus efficace dans un tel contexte est d’avoir les 2 infrastructures coexistant pendant une période donnée, et d’effectuer la bascule progressive des projets durant ce laps de temps, selon un calendrier qui aura été défini en amont. Cette solution permet aux projets de s’organiser et évite un big-bang qui bien souvent peut mal se passer. Bien entendu, cela accroit la charge de travail pour les exploitants, puisqu’ils doivent gérer plusieurs infrastructures en parallèle. Mais d’un autre côté, ils limitent la pression grâce à un calendrier adapté et en impliquant les équipes projets. Le point le plus notable est en fait l’acroissement du nombre de nœuds et des ressources nécessaires à cela (mais ces quantités peuvent être ajustées au fur et à mesure que les projets migrent).
Le dernier cas d’usage pour les questions d’architecture, concerne évidemment les déploiements multi-sites. Nous parlons ici de sites géographiques distants d’au moins un kilomètre. L’idée ici est de continuer de fonctionner, y compris si l’on devait perdre un data center (avec des stratégies actif/actif ou actif/passif). Cette nécessité peut elle-même être motivée par des considérations métier, avec certaines applications sensibles et/ou 7/24. Dans un tel cas, les architectes et exploitants devraient recrourir à plusieurs clusters installés en des sites différents, pour satisfaire ces exigences.
Les déploiements multi-sites peuvent prendre plusieurs formes :
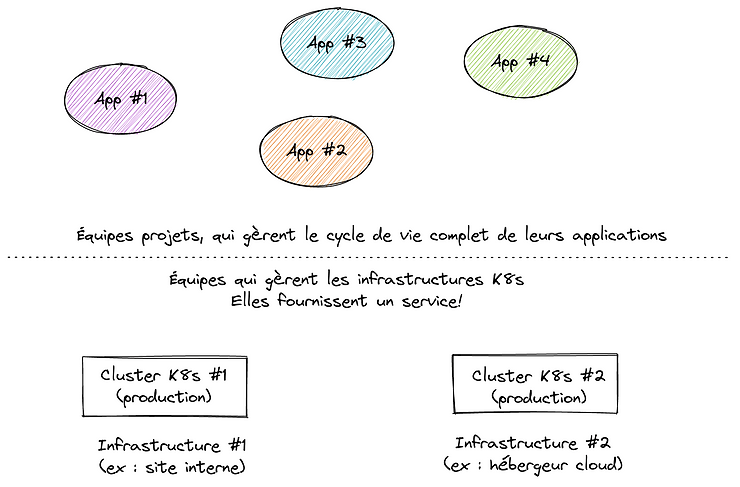
La deuxième catégorie d’impératifs qui peuvent motiver le recours à plusieurs grappes K8s tient à des exigences du métier. Bien sûr, l’architecture découle forcément de besoins métier. Mais nous parlons ici de situations liées directement au métier, à savoir la volonté d’adresser un marché particulier, et donc de fournir un ou des services à des clients.
Nous avons énuméré les nombreuses situations qui conduisent à travailler avec plusieurs clusters K8s. En général, c’est une combinaison qui prédomine. Ainsi, on peut très facilement imaginer une organisation avec un jeu de clusters (production / hors-production / bac à sable) sur un site interne pour des activités nationales, et une grappe hébergée dans le nuage, avec la même séparation entre environnements, mais pour un marché et des clients différents. Et peut-être qu’à un moment, une migration vers une autre solution K8s se posera et impliquera la mise en place d’un troisième groupe de clusters à gérer. En ce sens, travailler avec plusieurs clusters K8s apparaît comme la norme et non une exception.
Ceci étant dit, une question naturelle est de savoir s’il existe des situations où une unique grappe K8s peut suffire. Il y en a en effet quelques-unes. Le plus évident concerne les expérimentations et preuves de concept. Lorsqu’il s’agît d’explorer, un seul cluster suffit. Néanmoins, chez SoKube, nous avons rencontré plusieurs fois de tels clusters qui avaient évolué pour héberger en plus de la production. Pour des questions de coûts, et parfois de facilité, on s’en était tenu à un seul cluster, en s’appuyant sur les espaces de noms, des quotas, des politiques réseau et des nœuds dédiés, pour isoler différents environnements. Ces éléments résolvent bien la question de l’isolation des ressources, mais induisent un risque immense sur la maintenance, puisqu’une opération en erreur peut toucher tous les environnements, y compris la production. Démarrer avec un unique cluster K8s reste donc possible, mais doit toujours être considéré comme une étape intermédiaire. Dès lors que l’on envisage d’aller en production, plusieurs grappes seront nécessaires, in fine.
Ceci étant établi, les équipes en charge de leur exploitation doivent aussi tôt que possible se préparer à standardiser et industrialiser la gestion de leurs clusters (et des piles qui les accompagnent : supervision, centralisation des logs, sécurité…). Un cluster K8s ne devrait pas être un joyau patiemment poli que l’on ne veut / peut pas toucher. Au contraire, il s’agît d’adopter une approche d’usine, pour construire et reconstruire à l’identique autant de joyaux que nécessaire. C’est sans doute un sujet que nous aborderons plus tard dans un billet de cette collection.
Si ce sujet vous intéresse, vous pourriez aussi apprécier les articles suivants :
Enfin, mentionnons que la CNCF a lancé un groupe de travail sur les clusters K8s virtuels : c’est encore loin d’être opérationnel, mais cela pourrait ouvrir des possibilités en cas d’aboutissement.