
Par Maxime Ancellin.
Dans mon dernier article, je vous ai présenté des outils de gestion de dépendances et en particulier Renovate.
Maintenant, nous allons voir comment gérer notre infrastructure et ses applications comme n’importe quelles dépendances applicatives.
Cela nous permettra d’automatiser facilement les déploiements et de maintenir notre stack technique à jour.
Le tout se fera au travers d’un processus GitOps.
Si vous n’êtes pas familier avec ce terme, je vous invite à lire notre article dédié sur ce sujet: GitOps and the Millefeuille dilemma.
Ce post est la suite de l’article « La gestion automatisée des dépendances« , je vous invite donc à lire celui-ci au préalable.
La démarche présentée ci-dessous s’applique principalement à un environnement de petite taille, tel que celui d’une start-up ou d’une scale-up.
Ce type de contexte se distingue par une organisation allégée, avec très peu d’intermédiaires et des collaborateurs qui endossent souvent des responsabilités transversales.
L’ensemble de la chaine technique est contrôlé par une poigné de personnes et cela rend la gouvernance plus facile.
Cette approche diffère de celle d’une entreprise plus structurée, où des équipes spécialisées détiennent des responsabilités bien définies sur des périmètres spécifiques.
Pour explorer une perspective complémentaire, vous pouvez consulter cet article : Promouvoir les changements et les releases avec GitOps.
Nos infrastructures techniques ont beaucoup évolué ces dernières années avec les concepts de micro-services et de cloud native applications.
Cela implique de gérer de grands ensembles d’applications à jour, ce qui est indispensable pour garantir le bon fonctionnement des systèmes ainsi que leur sécurité.
Voici quelques bases importantes pour la suite.
Je ne vais pas rentrer dans le détail ici, mais nous allons décrire les caractéristiques de ce type d’application afin que nous soyons alignés pour la suite de cet article.
Afin de respecter ces quelques grands principes, en général, on a un projet Git pour chacun de ces services.
Cela complexifie donc grandement la gestion des applications à cause de leur grand nombre.
Pour pallier aux problématiques de gestion d’un nombre d’applications grandissant, nous avons cherché à automatiser un maximum les tâches redondantes de mise à jour des outils que nous embarquons.
Ce sujet a été traité dans mon dernier article.
Mais maintenant, se pose la question de la gestion de ces applications au sein de notre infrastructure. Ce qui fait qu’elles deviennent elles-mêmes une forme de dépendance.
En effet, nos applications sont versionnées et autonomes.
Pour une grande partie des systèmes modernes, ces applications embarquent dans leurs projets Git la création de leurs conteneurs, voire même de leur configuration de déploiement.
Cela permet d’avoir dans ce même projet et les versions l’ensemble des ressources qui rendent notre application « prête à déployer ».
Dans notre projet, nous ajoutons un dossier deployments, qui contient les configurations suivantes:
├── charts # Fichier de références pour Helm
│ ├── Chart.yaml
│ ├── default.yaml
│ ├── staging.yaml
│ ├── pre-production.yaml
│ └── production.yaml
└── configurations # Manifests Kubernetes
├── staging
│ └── secrets
│ ├── my-secret-a-sealed.yaml
│ └── my-secret-b-sealed.yaml
├── pre-production
│ └── secrets
│ ├── my-secret-a-sealed.yaml
│ └── my-secret-b-sealed.yaml
└── production
└── secrets
├── my-secret-a-sealed.yaml
└── my-secret-b-sealed.yamlMaintenant, nous allons voir comment il est possible de gérer notre infrastructure et ses applications comme n’importe quelle dépendance applicative.
Pour cela, nous allons avoir besoin d’un référentiel de nos projets Git/applicatifs.
Cela va nous permettre plusieurs choses :
Ce référentiel est pratique, mais cela ne nous permet pas de régler notre problématique d’environnement.
Afin de pouvoir gérer de multiples environnements, nous allons en créer un pour chacun d’entre eux.
Par exemple, je pourrai créer un Helm chart qui me permettra de déployer une liste d’applications (tout dépend de votre chaîne GitOps existante).
applications:
- name: frontend
sources:
- repoURL: git@github.com:my-org/frontend.git
targetRevision: 1.2.3
- name: api
sources:
- repoURL: git@github.com:my-org/api.git
targetRevision: 5.4.3Peu importe le format que l’on choisira, Renovate sera en mesure via un customManagers de type regex de retrouver la dépendance ainsi que la version.
Dans notre cas, nous pouvons utiliser la configuration ci-dessous:
renovate.json
{
"$schema": "https://docs.renovatebot.com/renovate-schema.json",
"separateMajorMinor": false,
"customManagers": [
{
"customType": "regex",
"fileMatch": [
"staging.yaml"
],
"matchStrings": [
"repoURL: (?<depName>.*?)n(( |n)*)targetRevision: (?<currentValue>.*)"
],
"datasourceTemplate": "git-tags"
},
],
"packageRules": [
{
"matchManagers": [
"custom.regex"
],
"matchFileNames": [
"staging.yaml"
],
"groupName": "release-to-staging",
"reviewers": [
"team:qa",
]
},
]
}Nous devons avoir un fonctionnement se rapprochant de celui décrit par les schémas ci-dessous :
Lecture du fichier référent nos applications
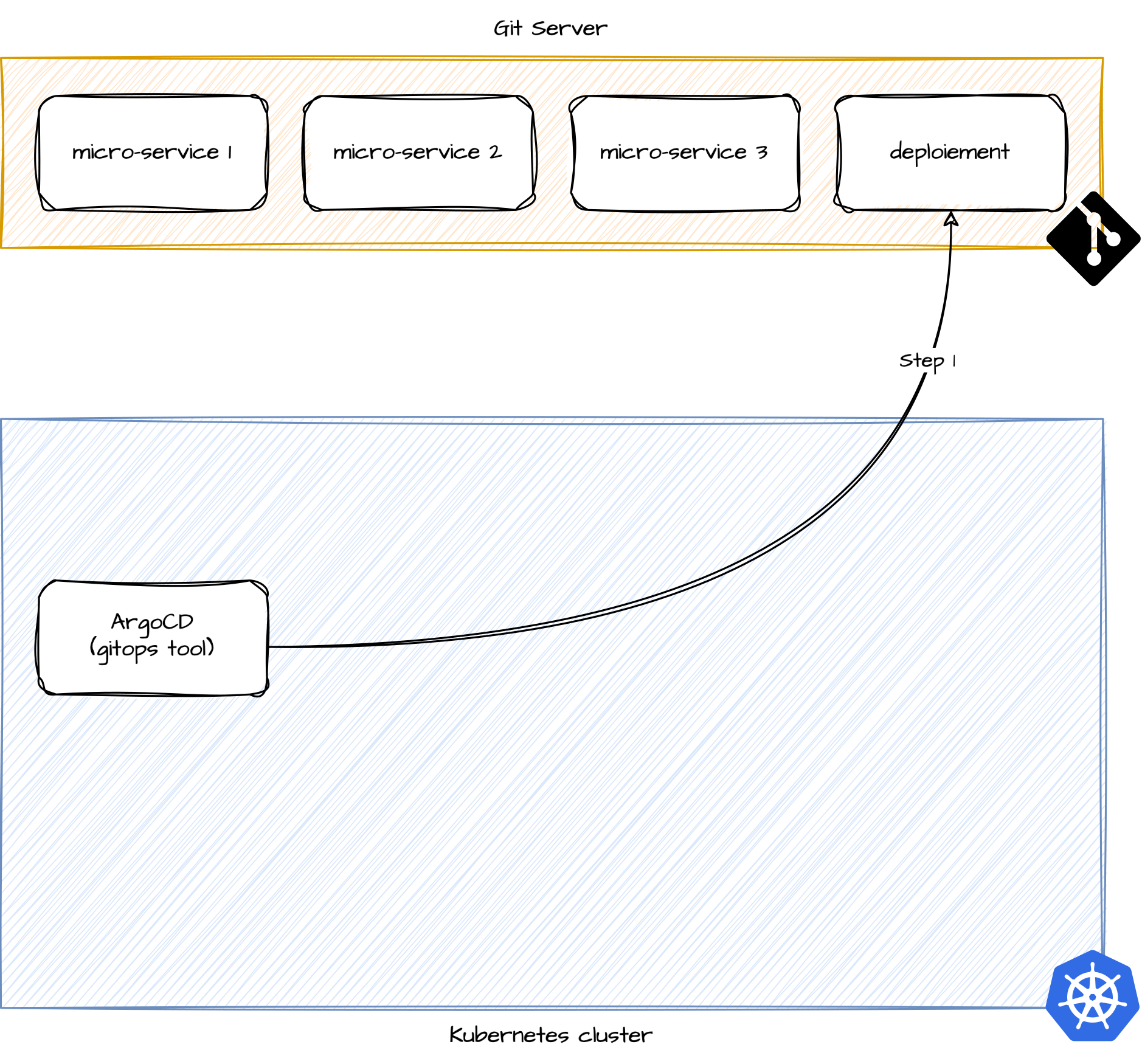
Lecture des projets Git applicatifs
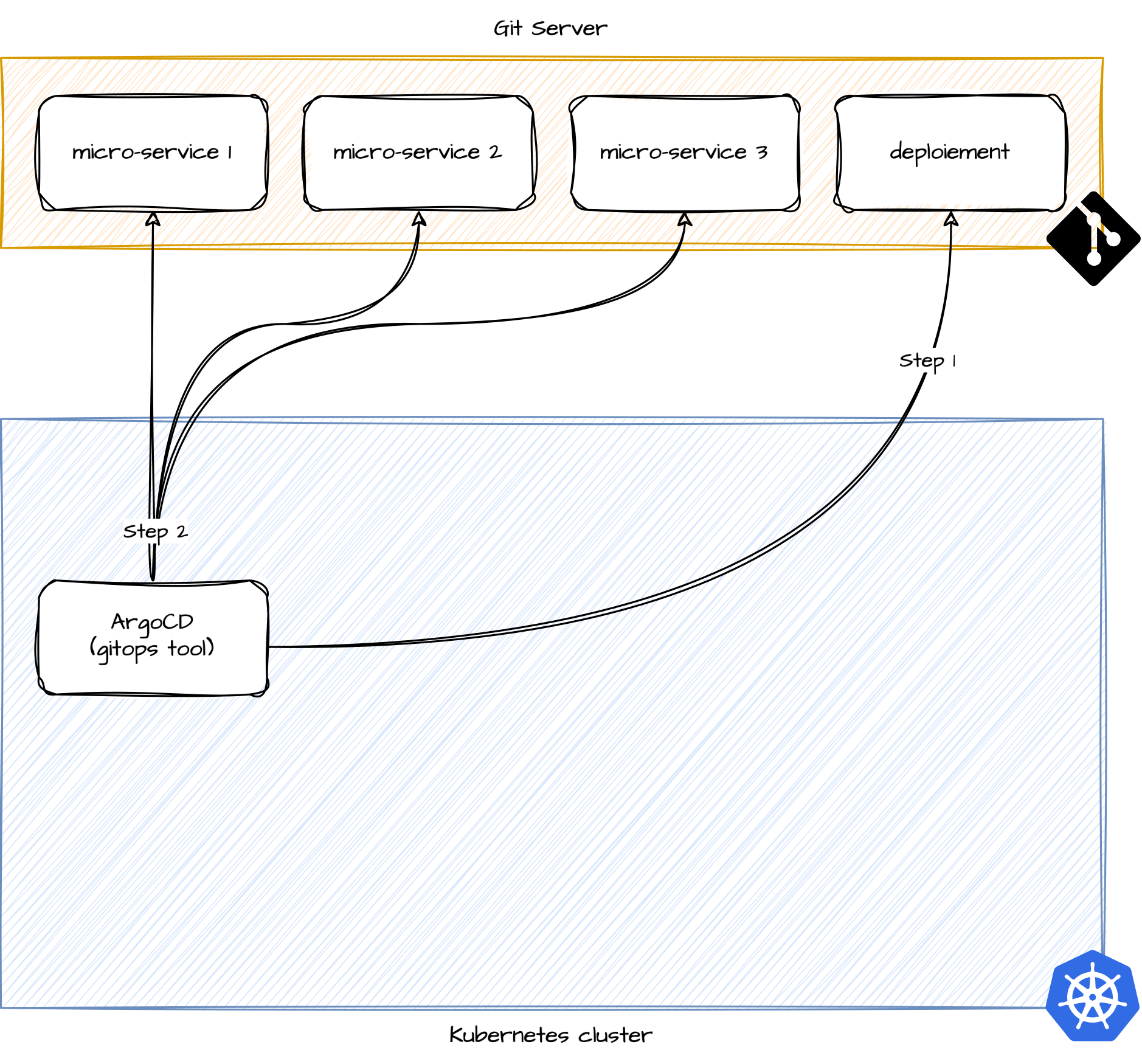
Déploiement des applications
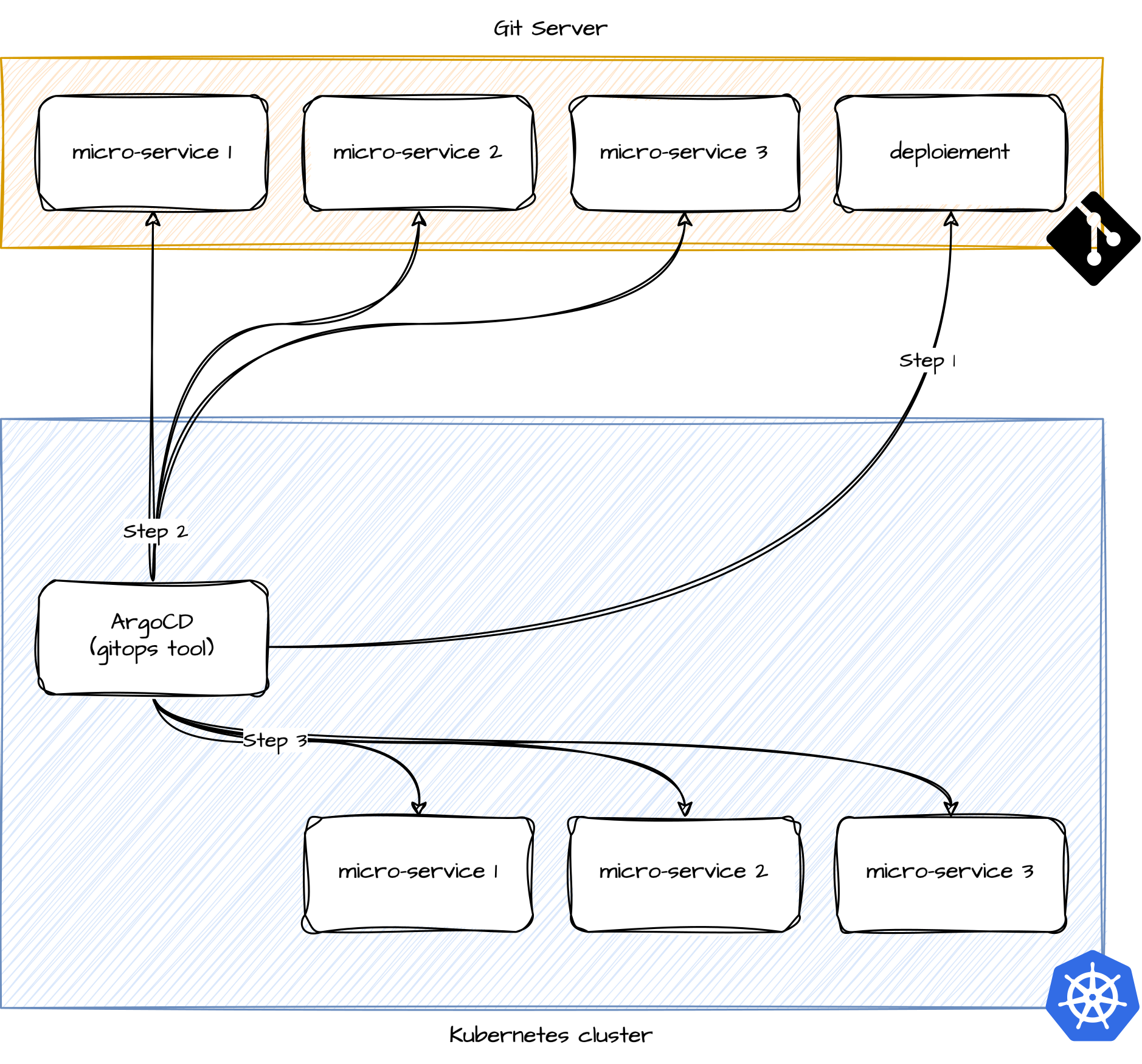
Maintenant que nous avons notre référentiel et que Renovate est capable de les interpréter, nous allons voir comment il est possible de gérer automatiquement les mises à jour et donc les mises en production.
Nous avons vu qu’il était relativement facile de gérer automatiquement les mises à jour des dépendances dans un fichier, malgré un format personnalisé.
Maintenant, il faut que nous puissions gérer la promotion entre les environnements afin d’éviter que tous nos environnements se voient proposer les mêmes mises à jour au même moment, sans respecter le processus de promotion entre les environnements.
Si nous reprenons notre fichier d’environnement de la section précédente et que nous partons du principe que nous avons les environnements suivants, avec chacun leurs règles :
La représentation du flux entre les environnements sera donc le suivant.
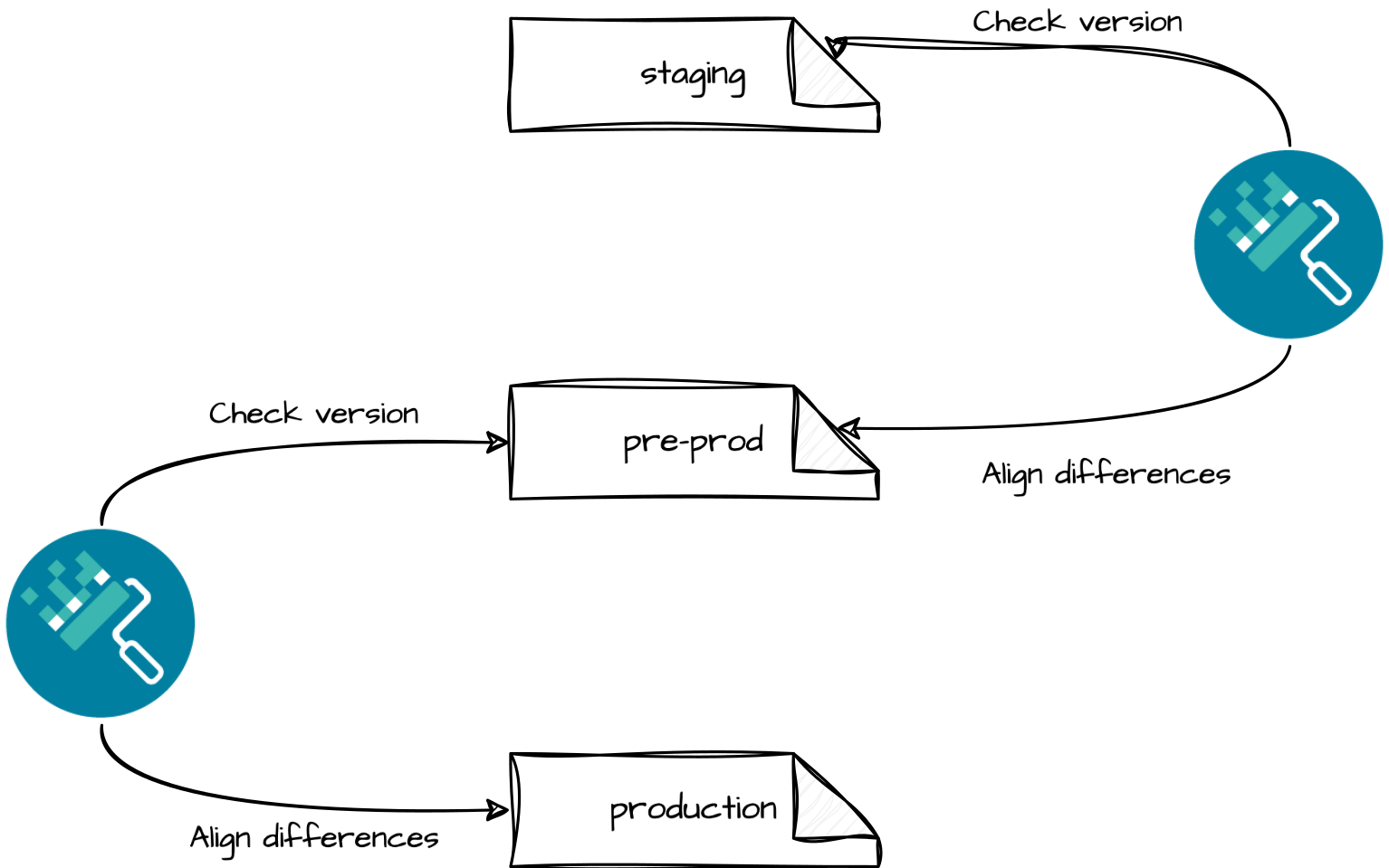
D’un point de vue de la configuration Renovate, nous allons devoir faire la configuration suivante:
{
"customDatasources": {
"localstaging": {
"format": "yaml",
"defaultRegistryUrlTemplate": "file://applications/staging.yaml",
"transformTemplates": [
"{"releases":[{"version": 'applications'.applications.sources[repoURL='{{depName}}'].targetRevision }]}"
]
},
"localpreprod": {
"format": "yaml",
"defaultRegistryUrlTemplate": "file://applications/preprod.yaml",
"transformTemplates": [
"{"releases":[{"version": 'applications'.applications.sources[repoURL='{{depName}}'].targetRevision }]}"
]
}
},
"customManagers": [
{
"customType": "regex",
"fileMatch": [
"applications/staging.yaml"
],
"matchStrings": [
"repoURL: (?<depName>.*?)\n(( |\n)*)targetRevision: (?<currentValue>.*)"
],
"datasourceTemplate": "git-tags"
},
{
"customType": "regex",
"fileMatch": [
"applications/preprod.yaml"
],
"matchStrings": [
"repoURL: (?<depName>.*?)\n(( |\n)*)targetRevision: (?<currentValue>.*)"
],
"datasourceTemplate": "custom.localstaging"
},
{
"customType": "regex",
"fileMatch": [
"applications/prod.yaml"
],
"matchStrings": [
"repoURL: (?<depName>.*?)\n(( |\n)*)targetRevision: (?<currentValue>.*)"
],
"depNameTemplate": "{{{ replace 'git@github.com:my-org/(.*).git' '$1' depName }}}",
"datasourceTemplate": "custom.localpreprod"
}
],
"packageRules": [
{
"matchManagers": [
"custom.regex"
],
"matchFileNames": [
"staging.yaml"
],
"groupName": "staging",
"automerge": true
},
{
"matchManagers": [
"custom.regex"
],
"matchFileNames": [
"preprod.yaml"
],
"groupName": "pre-production",
"reviewers": [
"team:qa"
]
},
{
"matchManagers": [
"custom.regex"
],
"matchFileNames": [
"prod.yaml"
],
"groupName": "production",
"reviewers": [
"team:leader"
]
}
]
}Nous avons donc une nouvelle notion qui est apparue depuis tout à l’heure.
La notion de customDatasources.
Une « datasource » personnalisé est défini par environnement sourçant un fichier YAML :
preprod.yml.prod.yaml.Chaque datasource est configurée pour lire le fichier YAML correspondant et extraire la version (targetRevision) d’une application via l’instruction transformTemplates.
Nous ne l’utilisons pas pour l’environnement de staging car nous utilisons directement les
git-tagsfournis par Renovate.
En général, nous aimons tous l’automatisation, car cela nous évite les tâches qui prennent du temps pour peu de valeur.
Mais il est toujours intéressant de voir plus loin.
Avec la proposition ci-dessus, nous pouvons éviter toutes les erreurs humaines sur les versions qui seront déployées sur les environnements.
Le fait que cela passe par des « pull requests » et que nous gérons cela en GitOps nous permet d’avoir une parfaite traçabilité des actions effectuées.
De plus, nous renforçons le processus de promotion entre les environnements, car l’outil se base uniquement sur l’environnement inférieur pour sourcer les nouvelles versions à déployer.
Vous avez également la possibilité de choisir le cadencement de Renovate afin de définir précisément votre rythme de déploiement.
Sans cela, votre limite sera uniquement la vitesse à laquelle vous itérez et fusionnez les changements.
Attention, afin d’arriver à une telle dynamique, il est important que vous ayez automatisé le reste du processus.
Sinon, vous allez vous retrouver rapidement bloqué à certaines étapes, et cela créera une frustration et de l’énervement autour des éléments bloquants.
Évidemment, ce genre d’automatisation peut bousculer beaucoup vos habitudes, mais cela apporte également de nombreux avantages.
Pour limiter la friction et faciliter l’adoption, voici quelques conseils.
Il est important de calquer votre architecture sur votre schéma organisationnel.
C’est-à-dire que votre architecture de sources GitOps doit parfaitement correspondre à vos équipes et que les droits configurés correspondent à votre hiérarchie.
Le risque de ne pas faire cela est que personne ne sera là ou ne pourra facilement autoriser les déploiements qui sont proposés.
Cela est globalement lié au GitOps, mais Renovate peut mettre en évidence les manquements lors de la mise en place de cela.
Afin d’avoir une meilleure visibilité sur les « pull requests » qui seront proposées, je ne peux que vous conseiller de maintenir un fichier changelog.md à jour dans votre Git.
Cela permettra à Renovate de l’inclure lors des propositions, et vous pourrez avoir l’ensemble des informations en un seul coup d’œil.
Si vous n’avez pas le temps de le faire, il existe de nombreux outils (Git-chglog, Conventional-changelog) permettant de le faire automatiquement.
L’automatisation ne veut pas dire aucun contrôle.
Cela permet de gagner du temps sur des tâches chronophages et de se concentrer uniquement sur l’essentiel.
Ce que nous permet de faire Renovate dans notre cas.
Il s’occupe de trouver les mises à jour à effectuer pour chacun de nos environnements, tout en nous les proposant afin que nous ayons « juste » à valider celles-ci.
Vous pouvez également travailler avec les packageRules afin de définir des notifications pour les personnes concernées par la « pull request » proposée.
Vous l’aurez compris avec ces deux articles sur Renovate: l’essayer, c’est l’adopter.
Une fois cela en place, il vous sera difficile de revenir en arrière.
En réalité, cela se fait avec relativement peu d’effort, mais vous apportera un gain de temps et d’efficacité considérable.
De plus, vous pouvez l’intégrer à plusieurs niveaux:
Le tout peut être sublimé via une approche GitOps.
Nous avons exploré comment cette approche permet de structurer efficacement les mises à jour à travers différents environnements, tout en garantissant un contrôle total via des « pull requests » et en respectant les processus de promotion.
Adopter cette méthode vous permet non seulement de réduire les erreurs humaines, mais aussi de fluidifier vos déploiements en conservant une traçabilité complète de chaque étape.
C’est une solution puissante et peu coûteuse pour optimiser vos pipelines de livraison continue tout en restant aligné avec les principes du GitOps.
Néanmoins, avant de mettre cela en place, pensez à adapter votre démarche à votre organisation.
Pour notre exemple, cela a été fait dans un context d’entreprise de taille petite/moyenne, tel que celui d’une start-up ou d’une scale-up.
Maintenant, à vous de faire vos mises en production en un simple clic !