
07 avril 2024
By Yann Albou.
Quel événement cette année ! Le plus grand de toute l’histoire de la Cloud Native Computing Foundation (CNCF) ! avec plus de 12 000 personnes !
Même en 3 jours de conférence, il était difficile de faire le tour, énormément de conférences, sponsors, discussions, soirées sponsors, …
Déjà plus de 10 ans de Kubernetes !
A cette occasion la CNCF propose que vous soumettiez votre logo du 10ème anniversaire de Kubernetes!: https://www.linuxfoundation.org/kubernetes-10-year-logo-contest
Sans surprise, le thème majeur de la Kubecon était l’Intelligence Artificielle en mode Cloude Native avec Kubernetes, mais pas que !
Voici un résumé, non exhaustif, des conférences qui m’ont intéressé en regroupant par thématiques:
La première keynote de Priyanka Sharma (Executive Director, Cloud Native Computing Foundation) s’est ouverte sur l’Intelligence Artificielle.
Le cloud Native n’échappera pas à cette tendance AI mais à clairement besoin de standards et d’outils.
Clairement, tout ça est en route et prendra une part importante dans cette accélération de l’IA avec le partage de modèles, de processus et de savoir-faire:
« Kubernetes doit devenir le standard de l’IA », Priyanka Sharma.
L’entraînement est la première phase d’un modèle d’IA. Le « training » peut impliquer un processus d’essais et d’erreurs, ou un processus consistant à montrer au modèle des exemples d’input et d’output.
La phase d’inférence représente l’exécution d’un modèle une fois qu’il a déjà été entraîné. Ainsi, l’inférence intervient après les étapes d’apprentissage. On peut également parler de phase de déploiement sur le terrain du modèle d’IA. Et donc, à cette étape, le modèle d’intelligence artificielle est déjà pré-calculé et a déjà été modélisé à l’aide de jeux de données (data sets). Ainsi, à ce moment, les systèmes d’intelligence artificielle peuvent tirer des conclusions ou des prédictions à partir des données ou connaissances qu’ils ont apprises.
Kubernetes et la CNCF se positionnent maintenant sur l’ensemble et utilisent la plateforme d’orchestration aussi bien pour gérer le cycle de vie du Machine Learning (AI/ML/LLM Ops) que pour faire tourner les modèles et les applications.
Un nouveau groupe de travail de la CNCF, la Cloud Native AI a publié un livre blanc sur les aperçus des techniques récentes d’IA/ML.
Introduction à l’initiative Cloud Native Artificial Intelligence (CNAI):
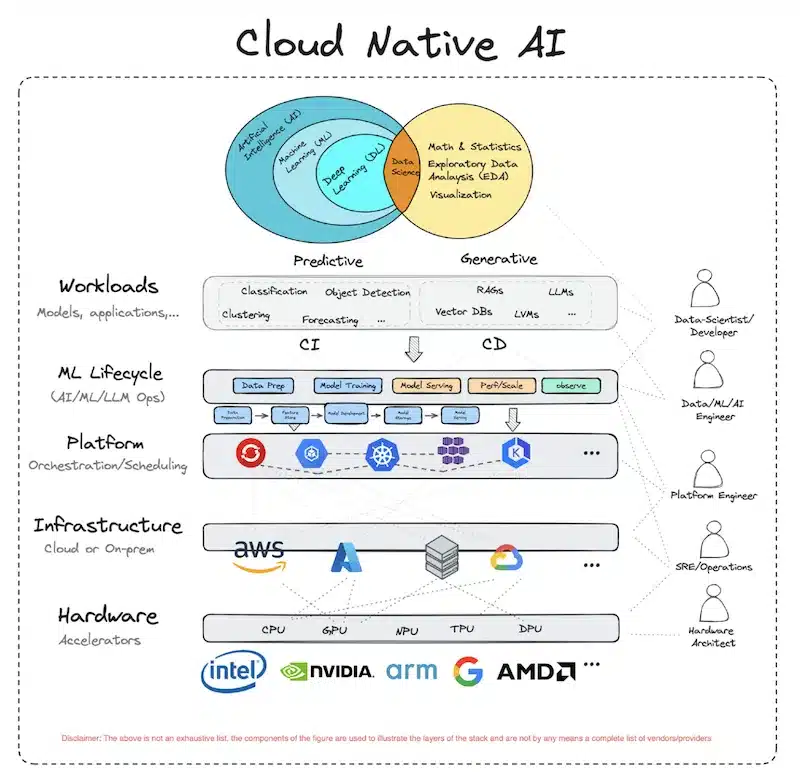
Cette tendance amène des évolutions de Kubernetes en particulier sur :
Les modèles de langage de grande taille (LLMs) gagnent rapidement en popularité et l’idée de déployer et de gérer son propre LLM peut être très intéressant, surtout en matière de sécurité, confidentialité, et customisation. Ce talk nous guide à travers le processus vers une compréhension claire et pratique de l’auto-hébergement des LLMs sur Kubernetes.
Auto-hébergement : Avantages et Considérations
Implémentation:

Voici la liste des LLMs Opensource
et un papier sur « tracking openness of instruction-tuned LLMs
Voir la vidéo de cette session
Une autre manière d’utiliser l’IA et les LLMs est l’utilisation des modèles de langage pour améliorer les opérations sur Kubernetes. Ils ont intégré les LLMs avec les CRD et controllers Kubernetes via un opérateur LLMnetes permettant de simplifier la gestion de cluster au travers une interface de langage naturel ressemblant à :
Ce projet souhaite aller plus loin avec des questions du type « Can I upgrade my cluster in 1.29 ? » qui nécessitera d’analyser les journaux d’audit, les ressources du cluster et lire le changelog.md des versions de k8s.
Attention : les LLM ne sont pas déterministes ! ! !
Comme mentionné : Évitez d’interroger un modèle d’apprentissage automatique pour des tâches nécessitant des données précises.
Voir la vidéo de cette session
Le build et le delivery restent des tendances fortes de la KubeCon avec des évolutions pour tenir compte du MLOps mais aussi beaucoup de conférences sur les aspects de sécurisation de la Supply Chain.
La keynote de Solomon Hykes (CEO, Dagger.io) sur le « Future of Application Delivery in a Containerized World » a retracé les 10 ans d’évolution de Kubernetes avec un message fort sur l’amélioration continue de l’usine logicielle, qui doit servir vos besoins et être un lieu central pour amener votre entreprise à un niveau supérieur comme un élément clé différenciateur :

En considérant aussi l’usine comme une plate-forme (là encore, l’ingénierie des plates-formes joue un rôle essentiel – on en reparle plus bas).
Plusieurs conférences très intéressantes autour des bonnes pratiques pour se prémunir au maximum des « Supply Chain Attacks ». Nous avions fait un blog sur cette thématique « Comment se protéger d’une “Supply Chain Attack” ? ».
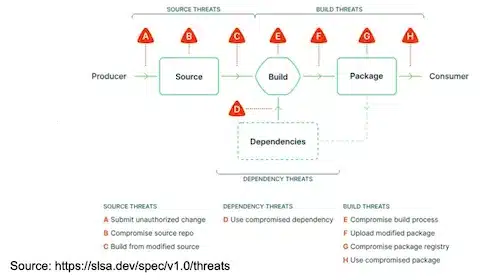
En particulier le framework de sécurité SLSA a été mis en avant:
SALSA (en version 1.0) définit les lignes directrices pour la sécurité de la chaîne d’approvisionnement avec différents niveaux et contient plusieurs « Tracks » en particulier la « Build track » qui se focalise sur la provenance (du source à l’artefact):
Scanner nos artefacts à la recherche de vulnérabilités est une excellente chose mais pas suffisant, il faut aussi se prémunir des problèmes de falsification de l’ensemble des éléments.
Alors comment augmenter le niveau de confiance de nos chaînes d’approvisionnement logiciel ? Et sur quoi repose ces approches :
Voici quelques outils utilisé
docker buildx build --sbom=true --provenance=true ...Il y a vraiment beaucoup d’outils pour sécuriser cette CI/CD:
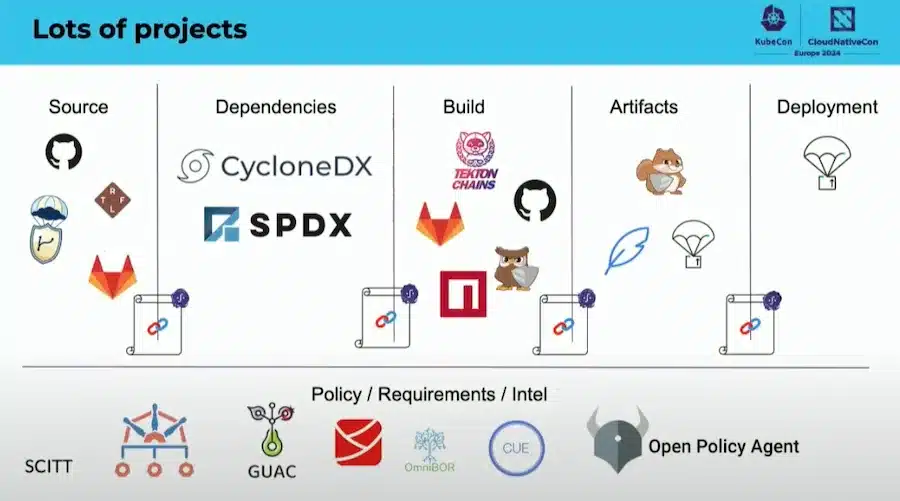
La CNCF travail sur un document pour mapper ces outils
N’oubliez pas non plus qu’il faut sécuriser votre code source ! En signant vos commits, protégeant vos branches, ayant une RBAC adaptée, une authentification via MFA, utilisation des clés SSH…
Pour démontrer l’ensemble la CI/CD Tekton avec les Tekton Pipeline a été souvent utilisée.
A noter aussi l’existence du projet FRSCA une « Factory for Repeatable Secure Creation of Artifacts: FRSCA » qui fournit des outils et une implementation du projet de la CNCF Secure Software Factory Reference Architecture et qui suit les recommandations SLSA.
Les pratiques de CI/CD autour des conteneurs se renforcent et gagnent en maturité. Trois conférences ont particulièrement attiré mon attention :
La conférence sur la construction des images docker de façon moderne a comparé plusieurs approches pour construire des images docker.
En partant de « l’ancienne manière » avec un Docker Build (qui produit des images qui ne sont pas reproductibles, trop volumineuses et avec beaucoup de CVEs)
FROM golang
WORKDIR /work
COPY . /work
RUN go build -o hello ./cmd/server
ENTRYPOINT ["/work/hello"]Pour aller vers une approche « Distroless Multistage Docker Build » de façon à n’avoir que le strict minimum dans l’image sans package manager ni shell…
Les images distroless sont construites avec
contents:
repositories:
- https://dl-cdn.alpinelinux.org/alpine/edge/main
packages:
- alpine-base
entrypoint:
command: /bin/sh -l
environment:
PATH: /usr/sbin:/sbin:/usr/bin:/binDans cette session, ils ont présenté plusieurs outils permettant de vérifier la conformité des charts Helm, dont Checkov, Datree, KICS, Kubelinter, Kubeaudit, Kubescape et Terrascan.
Ces outils testent et examinent si les charts Helm respectent les bonnes pratiques en particulier en matièrer de sécurité.
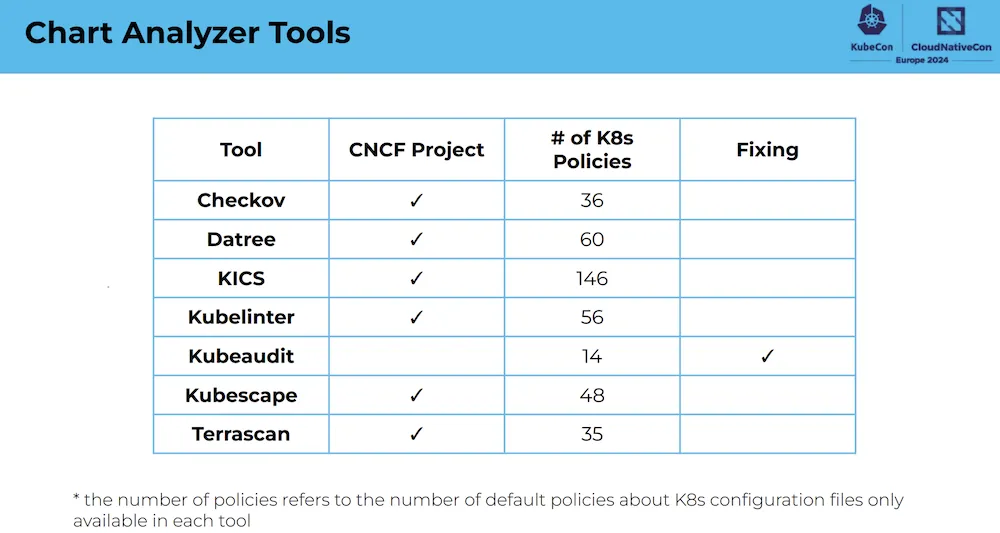
Le référentiel suivant contient une liste de Chart Helm public et a été utilisé pour tester les outils: https://github.com/fminna/mycharts
Plusieurs points intéressants ont été soulevés :
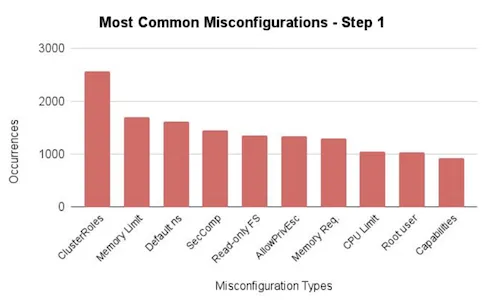
Par rapport aux outils les feedbacks sont:
Voir la vidéo de cette session
Suite à l’annonce sur Weavework annonçant que la société stoppait son activité, ont pouvait sérieusement s’inquiéter de la suite du produit GitOps Flux.
Cette présentation était rassurante sur l’avenir de ce produit:
Si a cela on rajoute le fait que Flux est un projet de la CNCF et qui est passé au niveau de maturité « Graduated » le 30 novembre 2022 cela nous permet de garantir une certaine pérénité de la solution !
Voir la vidéo de cette session
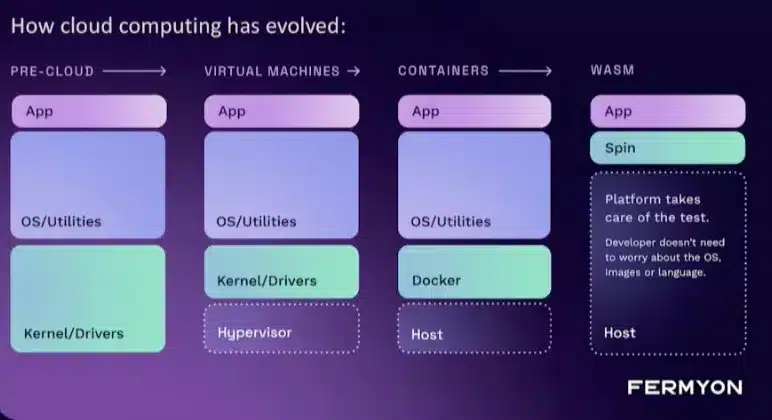
Ce n’est pas une technologie nouvelle mais elle était fortement présente durant la KubeCon et en particulier lors de la première keynotes.
WebAssembly est un format standard d’instruction binaire conçu pour remplacer JavaScript avec des performances supérieures. Le standard consiste en un bytecode, sa représentation textuelle et un environnement d’exécution dans un bac à sable compatible avec JavaScript. Il peut être exécuté dans un navigateur Web et en dehors
De nombreux langages de programmation possèdent aujourd’hui un compilateur WebAssembly, parmi lesquels : Rust, C, C++, C#, Go, Java, Lua, Python, Ruby, …
WebAssembly est très efficace, rapide et sécurisé ce qui le rend compatible avec le monde Cloud Native.
cette conférence, explore l’utilisation de WebAssembly dans Kubernetes au travers d’un outil SpinKubepin
Les forces de WebAssembly:
Fermyon, positionne WASM comme une évolution des containers pour des usecase adaptés:
En particulier, pour le pattern Serverless: Les conteneurs sont excellents pour exécuter des processus de longue durée, mais avoir une techno type WASM pour du Serverless qui peut démarrer à froid instantanément, s’exécuter jusqu’à la fin et s’arrêter.
Comment cela fonctionne:
Spinkube contient tous les éléments nécessaires pour faire tourner les applications WASM Spin dans k8s en se reposant sur les projets runwasi (pour la partie shim de containerd) et Kwasm pour la partie opérateur.
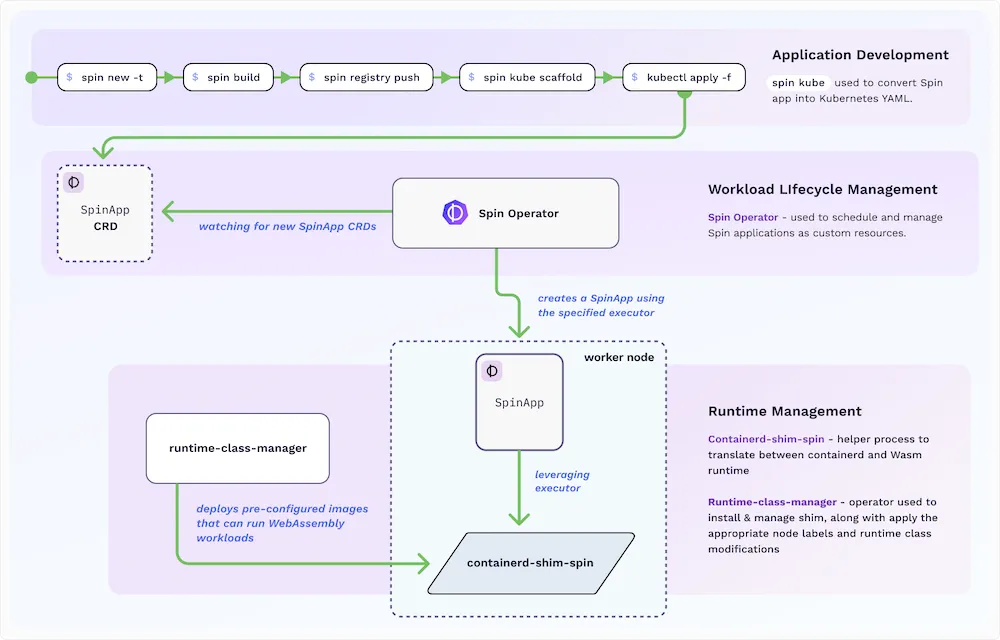
Il y a eu clairement un fort intérêt pour WASM et SpinKube de part les performances et son intégration dans le monde Cloud Native:

Voir la vidéo de cette session
On parle d’Intelligence Artificiel mais avons nous oublié le thème de l’année dernière sur la durabilité et l’éco-responsabilité ?
Le discours d’ouverture a appelé à « l’innovation responsable » : continuez à innover, mais faites-le en utilisant l’open source et en gardant à l’esprit les économies de coûts et d’énergie.
Les projets comme WASM vont dans ce sens, et les modèles de LLM rentrent dans un cycle d’optimisation de leur modèle, est-ce suffisant pour autant ?
Cette session montre des cas d’utilisation réel en entreprise sur la durabilité chez Deutsche Bahn.
Ils ont d’abord procédé à une optimisation entre l’utilisation moyenne du CPU machine et le CPU réel utilisé par l’application en forçant l’utilisation de la définition des requests et limits ainsi que l’utilisation des VPA (VerticalPodAutoscaler).
Puis ils ont utilisé des scheduleurs pour réduire ou arrêter les workloads qui ne servent pas pendant les heures non travaillées ou de moindre activitées…
En plus d’économiser beaucoup d’énergie cela permet aussi d’économiser de l’argent.
La mesure des coûts énergétiques est faite avec le projet Kepler:
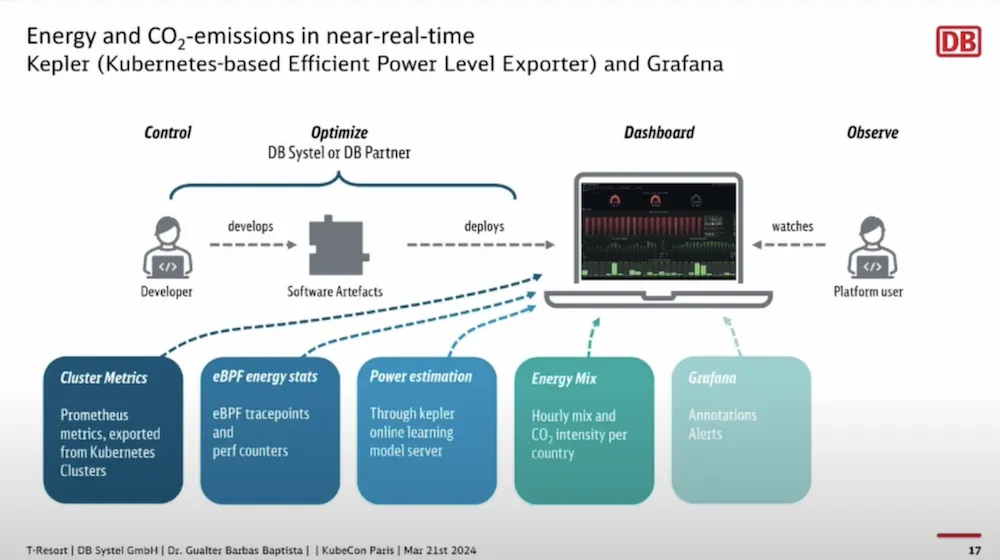
Cela permet de mesurer les impacts par projet ou même mesurer l’impact d’un changement à l’autre, et ainsi avoir un empreinte carbone globale et cibler.
Ces dashboards font maintenant partis de la vie des projets et constituent des informations pouvant influencer certaines décissions…
Voir la vidéo de cette session
Le TAG Environmental Sustainability soutient des projets et des initiatives liés à la fourniture d’applications cloud natives, notamment leur création, leur packaging, leur déploiement, leur gestion et leur exploitation.

Les objectifs de ce groupe sont:
Le score SCI aidera à calculer l’intensité carbone des logiciels:
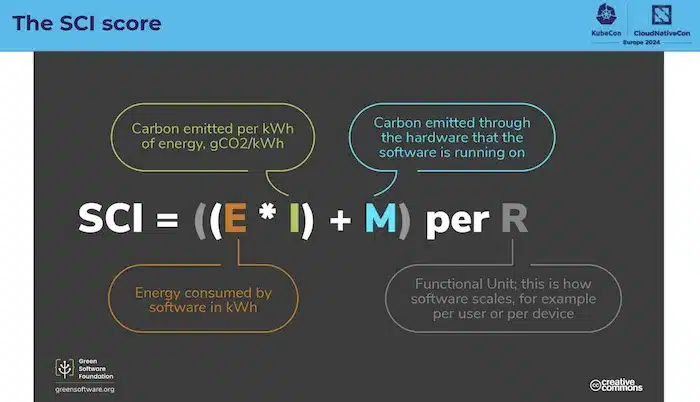
Et le but étant de produire ces métrics:
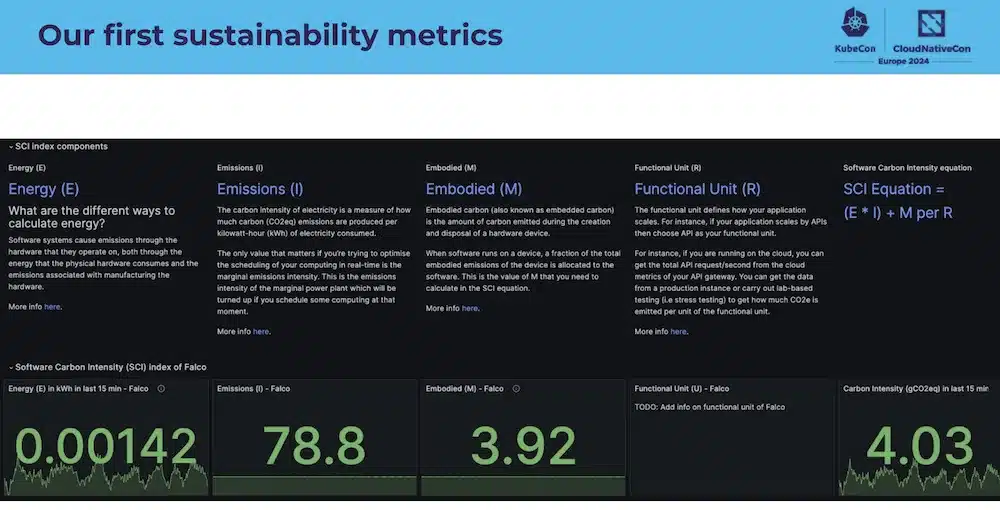
Le projet Falco a demandé sa première revue « Green » et d’autres projets de la CNCF vont suivres.
Voir la vidéo de cette session
Beaucoup de tracks sur l’observabilité avec en particulier un focus sur Opentelemetry mais aussi sur l’IA.
Le projet OpenTelemetry est partout et largement utilisé

Juste sur le mois précédent cette KubeCon il y a eu 25 000 contributions !!!
Bref sa popularité n’est plus à démontrer.
News côté logging:
OpenTelemetry définit des « Semantic Conventions » qui spécifient des noms communs pour différents types d’opérations et de données ce qui permet d’amener des standards sur le codebase, les librairies et les plateformes.
Les Semantic Conventions sont disponibles pour les traces, metrics, logs et ressources le tout en version stable pour la partie HTTP.
Et travail en cours sur les parties Databases, Messaging, RPC, System et le nouveau petit dernier AI/LLM !!!
Extension des signaux OpenTelemetry sur la partie « Client-side » et pas seulement au niveau applicatif et infrastructure.
Définition d’un nouveau concept « Entity » pour mieux représenter le producteur de la télémétrie.
Le projet OpenTelemetry a postulé pour être un projet « Graduated » de la CNCF et ainsi démontrer sa stabilité et sa maturité.
Voir la vidéo de cette session
Le groupe de travail « Observability TAG » vise à enrichir l’écosystème des projets liés à l’observabilité dans les technologies natives du cloud, en identifiant les lacunes, en partageant les meilleures pratiques, en éduquant les utilisateurs et les projets CNCF, tout en offrant un espace neutre pour la discussion et l’implication communautaire.
L’observabilité Whitepaper est disponible.
Il se concentre sur l’amélioration de l’observabilité dans les systèmes cloud-natifs, offrant une vue d’ensemble des signaux d’observabilité, tels que les métriques, les logs et les traces, et discute des meilleures pratiques, des défis et des solutions potentielles. Il vise à clarifier le concept d’observabilité, fournissant des informations précieuses pour les ingénieurs et les organisations cherchant à améliorer la fiabilité, la sécurité et la transparence de leurs applications et infrastructures cloud-natives.
Le TAG observability a co-sponsorisé le Cloud Native AI workgroup (voir le chapitre AI plus haut) et a revu plusieurs projets autour de l’AI:
Il y a clairement une tendance « Observability + Gen AI » afin de :
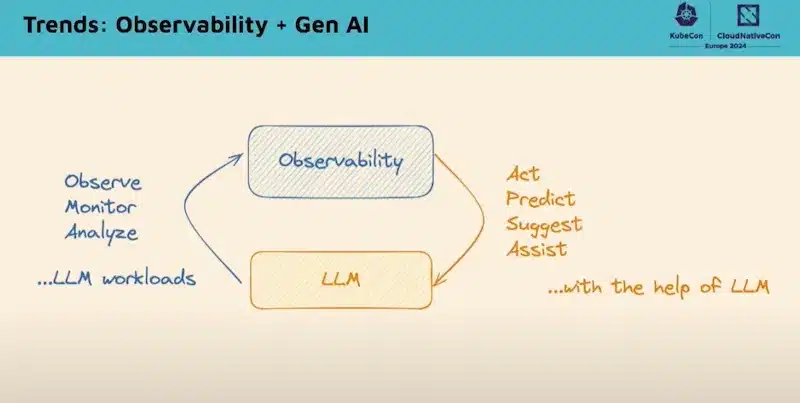
Voir la vidéo de cette session
L’IaC n’était pas une tendance de la conférence, il n’y avait pas de session dédiée par exemple à Terraform ou Ansible.
Par contre dans la plupart des conférences ces outils d’Infra-as-Code étaient utilisés comme socle de base !
De plus il y a quand même 2 points notables sur ce domaine:
Le premier concerne les multiples échanges et discussions informelles autour de Terraform suite au changement de licence par HashiCorp (Business Source Licence: BSL v1) qui a amené à un fork de la release 1.5 de Terraform pour créer le projet OpenTofu !
Terraform est fortement implanté dans les entreprises et projets et selon l’évolution de ces 2 projets, cela pourra amener beaucoup de changement… A suivre
Le second point concerne la forte présence de Crossplane qui gagne sérieusement en popularité et qui est, sans aucun doute, un projet très intéressant.
Crossplane est un outil d’IaC qui se définit comme un « Cloud Native control plane » pour provisionner et gérer toutes vos ressources en se basant sur Kubernetes !
C’est un projet très implanté dans l’éco-système de la CNCF et surtout production ready:

Toutes les ressources sont gérées depuis kubernetes au travers de CRD et Crossplane gère la communication vers des ressources externes comme AWS, Azure ou Google Cloud.
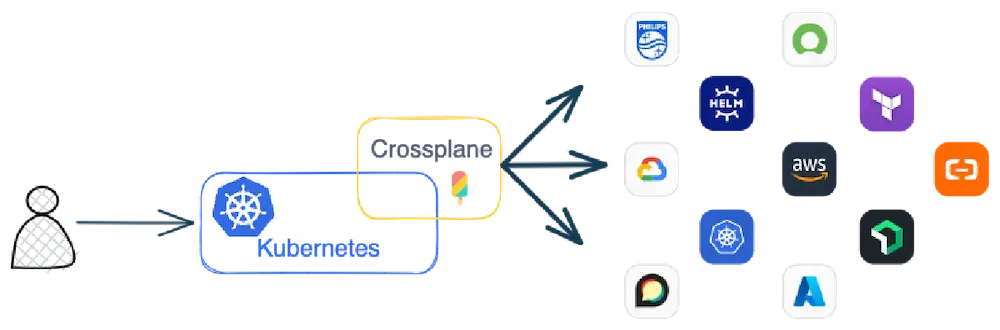
Il existe un Marketplace communautaire avec une liste de providers dont certains sont donnés par Upbound (La société derrière Crossplane))
Crossplane permet également la création d’API Kubernetes personnalisées. Les équipes de plateforme peuvent combiner des ressources externes et simplifier ou personnaliser les API présentées aux consommateurs de la plateforme.
Et donc vous pouvez créer votre propre platform API: par exemple composer un GKE en mode Platform Engineering.
Voir la vidéo de cette session
Cette session n’était pas une présentation mais une discussion avec un panel de personnes qui ont partagé leurs avis et leur vision sur l’évolution de l’Infra-as-Code.
Plusieurs points intéressants :
Mais à la fin, la migration entre les outils IaC est toujours un effort important.
Voir la vidéo de cette session
Lors de la KubeCon EU en 2022 la tendance était au Plateform Engineering, cette année le platform engineering n’est plus une tendance mais une réalité.
Les outils et frameworks d’infrastructure, tels que Kubernetes, les service Meshs, les gateways, la CI/CD, etc…, ont bien évolué et sont largement considérés comme des « technologies classiques » (du moins pour ce public spécialisé). Le grand défi consiste désormais à assembler les pièces du puzzle pour apporter de la valeur aux clients internes.
Voir notre article sur ce qu’est le Platform Engineering et les liens avec le DevOps
Le « sponsor showcase » été plein de mentions sur les plateformes, l’ingénierie des plateformes et l’expérience des développeurs, avec en particulier:
Humanitec, Backstage, Port, Cortex, Kratix, Massdriver, Mia-Platform, Qovery, …
On voit même apparaître des langages de spécification de workload comme Score et Radius pour amener une couche d’abstraction entre la demande du développeur et la réalisation technique par le Platform Engineer.
L’incontournable Backstage pour l’IDP (Internal Developpeur Platform) est le projet auquel les utilisateurs de la CNCF ont le plus contribué !
Après 4 ans d’existance il y a plus de 2,4k adoptants et 1,4K contributeurs !!!
Le projet continue de travailler sa maturité sur la gouvernance en proposant un processus d’amélioration: Backstage Enhancement Proposals qui est largement inspiré par le Kubernetes Enhancement Proposals (KEPs)
Voici les nouveaux domaines de ce projet :
L’évolution de Backstage se poursuit avec un axe de simplification qui sera, sans aucun doute, très apprécié !
Voir la vidéo de cette session
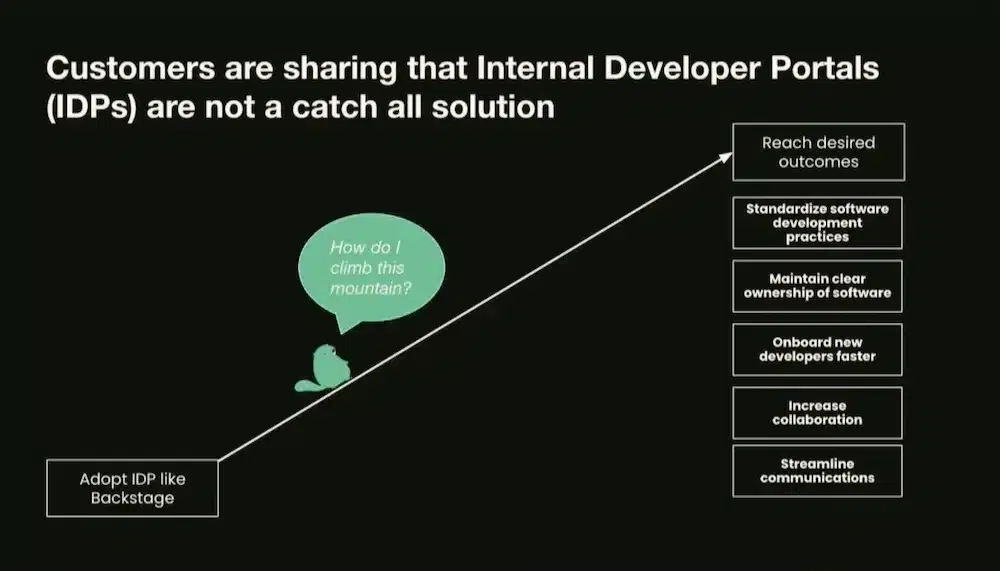
Cette session faisait le focus sur l’approche produit pour développer la plateforme en décrivant qu’est-ce qu’une « Platform Product » chez Spotify.
Et avant tout c’est un changement d’état d’esprit en mode « Platform as a Product Mindset » qui change la manière de faire un IDP et la gestion des produits internes.
Avoir un portal n’est pas suffisant, l’orientation produit consiste à orienter les résultats souhaités et à créer une valeur continue et itérative pour atteindre ces résultats:
 )
)
Cette approche permet aussi d’optimiser les opérations, réduire les coûts et s’aligner sur les tendances du marché.
Le but étant de se focaliser sur les résultats en analysant la valeur (quelle problème on cherche à résoudre) et la viabilité (Qui sont les clients et pourquoi ils utilisent la plateforme).
Et sortir du mode « cool on adopte une nouvelle techno à la mode », « il y a un seul besoin, faisons une nouvelle solution », …
Il est nécessaire de comprendre le besoin business et de développer une « Customer Empathy » en discutant régulièrement avec son client et pas seulement un membre de l’équipe.
Mais aussi de comprendre les motivations des différents users et managers jusqu’au CTO, c’est l’idée de « l’empathie de déploiement » et ainsi avoir la vision globale pour délivrer une solution aussi adaptée aux décissionnaires.

Voir la vidéo de cette session
Evidemment, Kubernetes, le coeur de la KubeCon, était fortement présent !
Après plus de 10 ans d’existant, il continue d’évoluer, de s’enrichier et de s’adapter aux besoins et aux nouveautés du marché.
Cette session explique les patterns principaux de K8S, comprendre ces modèles est crucial pour saisir l’état d’esprit de Kubernetes, et renforcer notre capacité à concevoir des applications dîtes Cloud Native pour quelles s’incrivent au mieux dans cette démarche.
Les patterns par catégorie:
Il y a plein d’autres patterns, voir le livre « Kubernetes Patterns »
Voir la vidéo de cette session
Je trouve extrêmement intéressant de regarder le processus de Release de Kubernetes par le Kubernetes SIG Release Group.
Kubernetes est un produit complexe composé de multiples composants avec des équipes multiples de sociétés différentes et distribuées dans le monde entier le tout avec un cycle de release exigeant. Et ça marche !!!
De part cette complexité, c’est toujours compliqué en entreprise de faire partie de l’équipe de Release et les attentes ne sont pas toujours au rendez-vous !

La documentation est un point crucial et un prérequis pour les améliorations faisant parties des releases Kubernetes.
Avoir une phase de « Docs Freeze » est importante tout comme les phases de « Code Freeze » pour amener des phases de stabilisation.
Kubernetes v1.30 « Uwubernets » est en cours:

La roadmap 2024 pour le SIG Release est d’avoir un Release Pipeline plus robuste, plus rapide et plus flexible.
Le build de package k8s se fait avec OpenBuildService de Suse qui permet de travailler avec toutes les principales distributions Linux. Les packages sont ensuites publiés sur pkgs.k8s.io
Les actions de releases sont faites avec GitHub Actions, en utilisant des steps de création de Provenance, de SBOMS, Check Dependencies et de publication de release et de release notes.
Tout le procesus de release est décrit dans le repository kubernetes
Le futur est de créer une Supply Chain véritablement sécurisée: SBOMS, Provenance, Signature fait déjà partie du processus mais peu les utilise ou s’appuie dessus.
Il va y avoir un nouveau flux de sécurité Kubernetes avec un Security Response Committee (SRC)
Il y clairement beaucoup de choses à en tirer pour l’appliquer sur nos propres Release même sur des projets non Opensource mais en mode « InnerSource »
Voir la vidéo de cette session
Les NetworkPolicy sont une importante fonctionnalité de kubernetes gérées par le SIG Network et permettent de sécuriser les flux de communications entre les pods.
Elles ont été pensées pour les dev avec un design d’API implicit (refus implicite, liste d’autorisation explicite des règles).

Apparition de 2 nouveaux objets: AdminNetworkPolicy et BaselineAdminNetworkPolicy en v1alpha pensés, cette fois, pour les Admins avec un mode explicit.
Les usecases:
L’API AdminNetworkPolicy a la priorité sur l’API NetworkPolicy.
L’API BaselineAdminNetworkPolicy correspond à une posture de sécurité par défaut du cluster en l’absence de NetworkPolicies
Plusieurs propositions d’amélioration: Network Policy Enhancement Proposals (NPEP):
Future Plans: Network Policy V2?
Voir la vidéo de cette session
Les services Mesh deviennent incontournables lorsque l’on fait des micro-services dans kubernetes, les avantages sont multiples:

Les services Mesh ont largement adoptés l’approche des Sidecar containers afin d’amener le réseau au plus près de l’application sans être intrusif mais viennent aussi avec des incovénients (Difficulté de sizer, Security, upgrade challenging, …)
L’utilisation d’eBPF pour les Services Mesh permet de résoudre certains de ces problèmes ce qui n’exclus pas le besoin d’avoir un proxy:
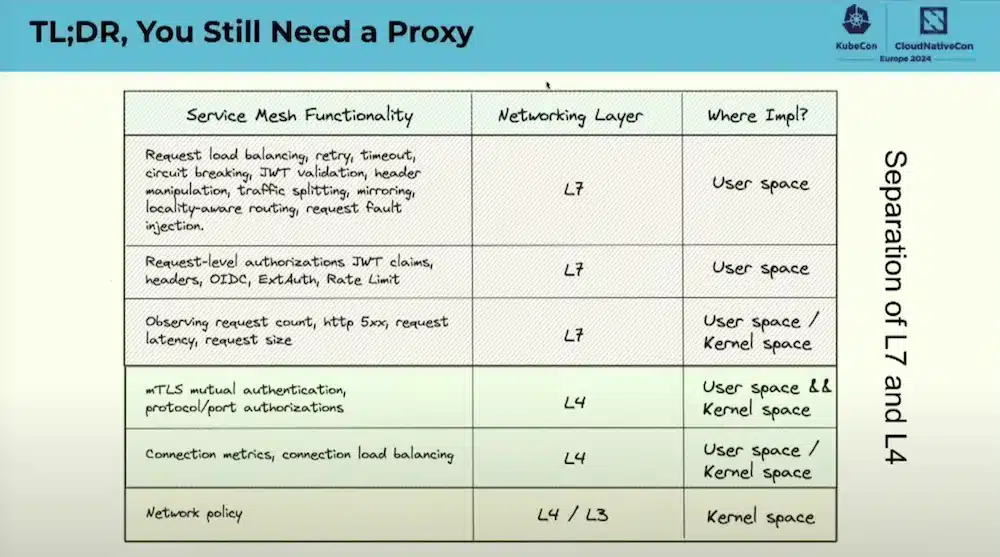
La comparaison entre Cilium et Istio en mode « Sidecarless » ou en mode mixte (Séparation des layer 4 et 7) explique clairement les differentes architectures et le fonctionnement de ces 2 Services Mesh.
Voir la vidéo de cette session
La question de la base de données dans Kubernetes est récurrente. Est-ce production ready si on utilise des opérateurs ?
Ce comparatif a choisi quelques opérateurs de Base de donnée (PostgresQL, MySql, MariaDB) par rapport aux fonctionnalités de setup, d’Observabilité, de backup restore, d’upgrade, …
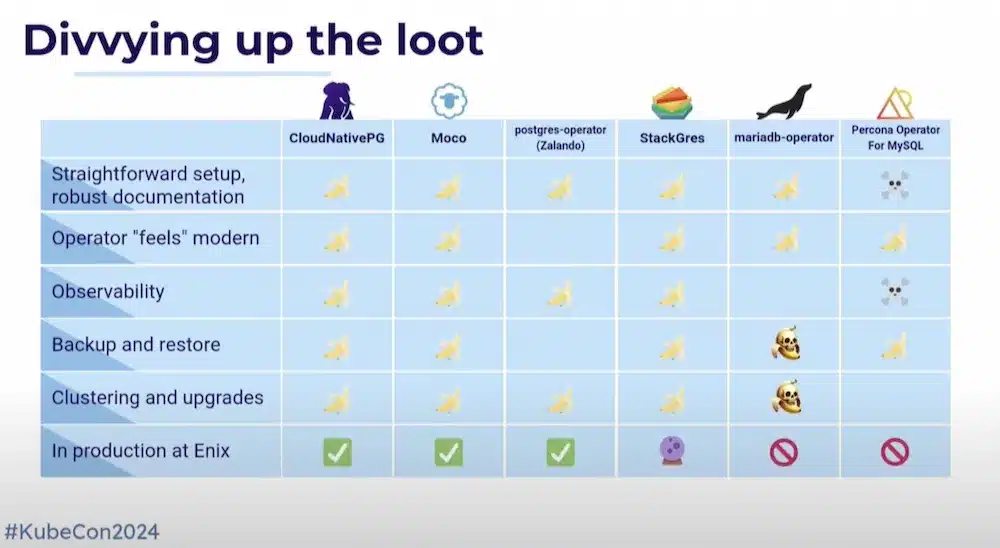
Retour d’expérience intéressant basé sur leur expérience réelle de production, et noté à l’aide d’icônes Banane (bon), Tête de mort (moins bon) ou un mélange des deux (amélioration par rapport aux versions précédentes).
Voir la vidéo de cette session
Pour aller plus loin par rapport à la session précédente sur les opérateur de base de données, cette présentation explique les avancées sur le storage kubernetes: Plus de workload Statefull vers K8S : automatisation, évolutivité, performances, basculement !!!
Il existe un livre blanc pour clarifier la terminologie, expliquer comment ces éléments sont actuellement utilisés en production dans des environnements de cloud public ou privé et comparer les différents domaines technologiques.
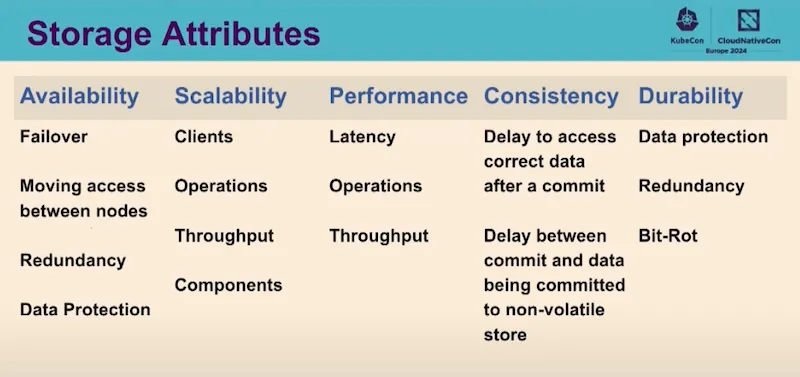
Un focus sur les database avec aussi un livre blanc « Data on Kubernetes Whitepaper – Database Patterns » qui explique bien les modes de fonctionnement :
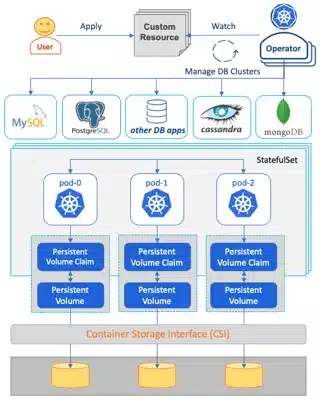
Il est intéressant de voir que l’Operatorhub contient 349 operators dont 47 db operators avec 9 PostgreSQL opérateurs.
Un point essentiel lorsque l’on gère des données dans Kubernetes est l’aspect Disater Recovery
Il existe plusieurs approches décrites dans ce document
Les prochains focus seront sur les données et workload AI/ML…
Ainsi qu’un livre blanc sur les performances.
Voir la vidéo de cette session
La sécurité était partout, sur l’ensemble des thématiques avec des approches zero-trust.
En particulier, les chaînes d’approvisionnement sécurisées ont été largement mentionnées dans les outils de construction de conteneurs (aux côtés du SBOMS et de SLSA): voir le chapitre Supply Chain plus haut.
La sécurité des réseaux était aussi bien présente, avec des mentions intéressantes de Cilium (et eBPF dans ce contexte), Linkerd et Istio.
Je retiens cette présentation où le public a pu choisir les outils de sécurité pour protéger une application dans kubernetes:

Outre les démonstrations sucessives des outils, ce qui était très intéressant c’était de voir le choix des outils par l’audience:
Voir la vidéo de cette session
La KubeCon 2024 a marqué un tournant décisif dans l’évolution de Kubernetes et de l’écosystème Cloud Native, en mettant particulièrement l’accent sur l’intégration de l’intelligence artificielley, tout en soulignant l’importance de la sécurité, de la Supply Chain, de la durabilité, de l’infrastructure-as-code et de WebAssembly.
Ces thématiques montrent une maturité et une vision à long terme, préparant le terrain pour des innovations futures.
Le large spectre de sujets abordés, allant de la supply chain sécurisée aux meilleures pratiques en matière d’observabilité et d’opérations, confirme l’engagement de la communauté envers une amélioration continue. Kubernetes, au cœur de ces discussions, prouve une fois de plus qu’il reste à l’avant-garde de la technologie, prêt à relever les défis futurs du Cloud Native.