By Yann Albou.
Le Platform Engineering est un enjeu majeur pour les entreprises et les organisations qui souhaitent développer des produits numériques puissants, évolutifs, sécurisés et répondant aux enjeux du métier. Qu’est-ce que le Platform Engineering ou l’Internal Developer Platform (IDP) exactement ?
La notion de plateforme n’est pas nouvelle mais quelle est la différence avec du SaaS classique ?
Comment peut-elle aider les entreprises à créer des produits et services efficaces et scalables ? Quelles sont les meilleures pratiques et les outils essentiels pour réussir dans ce domaine ?
Dans cet article, nous explorerons en détail le monde du Platform Engineering et de l’Internal Developer Platform et répondrons à toutes ces questions afin de vous aider à comprendre les fondements de cette évolution stratégique.
Sur ce même thème Sokube a organisé une table ronde. Le replay est disponible ici :

A l’origine, l’approche DevOps a émergé afin d’améliorer la rapidité, l’efficacité et la qualité du développement logiciel en automatisant les processus, en favorisant une communication transparente et en encourageant la responsabilité partagée.
En cassant le fameux mur DevOps, et donc en rapprochant les différents acteurs de la chaîne d’approvisionnement (en particulier les Dev, la Sécurité, les Ops), le DevSecOps met l’accent sur la création d’un cycle de développement continu et d’un déploiement continu, en intégrant les pratiques Agile, la gestion du code source, l’automatisation des tests et des déploiements, la sécurité et la qualité.
Le but est de résoudre les problèmes de communication ce qui représente déjà une énorme amélioration par rapport à l’approche traditionnelle.
Concrètement, cela se traduit par une équipe DevOps en charge d’une application avec la responsabilité de gérer la containerisation, la CI (Continuous Integration), la CD (Continuous Delivery / Deployment), Kubernetes, l’infrastructure (IaC avec Terraform ou Ansible par exemple), Gestion des comptes Cloud, l’observabilité, la sécurité, les upgrades, le patching, … le tout sur les différents environnements !
Avec l’ensemble de ces responsabilités vient la charge cognitive (j’aborderai ce point en détail par la suite) de la gestion de l’ensemble de ces outils et process en plus du restant (en particulier l’application Business).
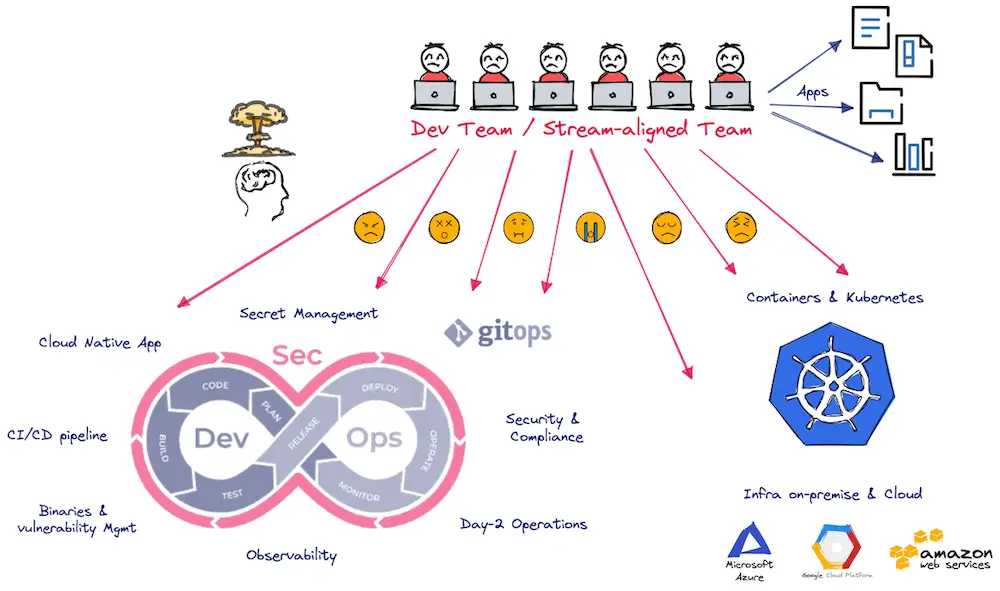
Avoir cette approche pour chaque application ou groupe d’applications ne passe pas la mise à l’échelle.
Pour chaque équipe qui va gérer des applications, les défis et besoins techniques sont très proches. La factorisation et la centralisation deviennent donc des éléments clés pour maximiser l’efficacité et éviter un effet d’inconsistance au niveau entreprise.
Pour autant, l’autonomie, l’innovation et la liberté des équipes restent nécessaires surtout lorsqu’on applique le principe SRE « You build it you run it ». Mais cela ne peut pas fonctionner si l’équipe doit en plus gérer la plateforme, l’opérer et la maîtriser.
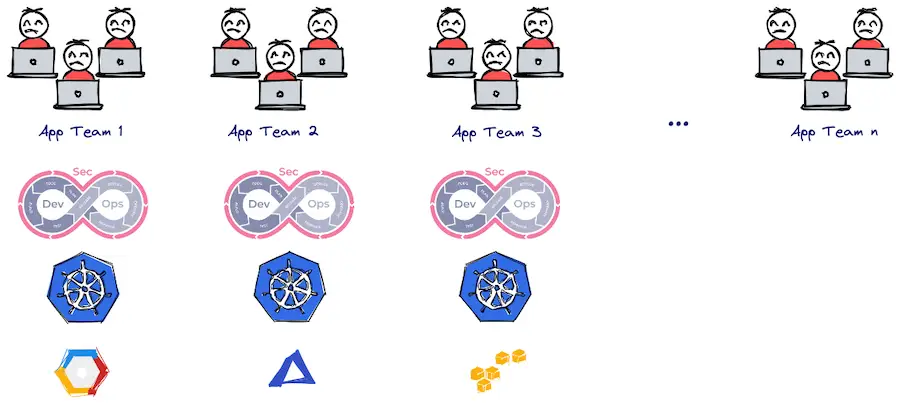
Si on rajoute en plus le besoin d’expertise sur chacun de ces sujets, il devient alors quasi impossible, pour une équipe business en charge d’une application, de construire une plateforme efficace, sécurisée, compliante, fiable et performante.
Bref, vous l’aurez compris, savoir configurer correctement kubernetes pour son application, savoir comment mettre en place le scanning des images sur les différents environnements, savoir automatiser le déploiement sans interruption de service ou savoir mettre en place une solution d’observabilité n’est pas forcément la meilleure utilisation des ingénieurs de développement sur lesquels reposent déjà beaucoup de responsabilités !
Le Cloud Maturity Model de la CNCF cartographie le parcours de transformation DevOps en plusieurs étapes: Build -> Operate -> Scale -> Improve -> Optimize, en analysant plusieurs critères : People, Process, Policy, Technology, Business outcomes.
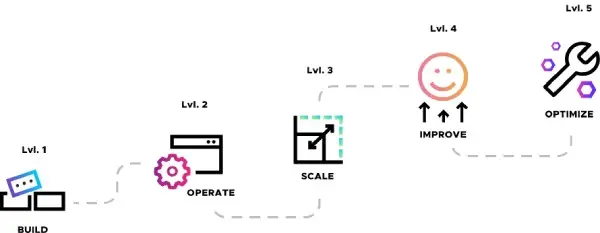
Ce modèle de maturité montre bien qu’au fur et à mesure que l’entreprise mûrit et évolue, elle comprend de mieux en mieux l’impact de ses outils et améliore et affine ses pratiques DevOps. Ce même modèle permet de mettre en évidence les problèmes d’inefficacité et le besoin de consolidation avec une plateforme mutualisée.
Avant d’expliquer en détail ces concepts, commençons par une simple définition :
Le Platform Engineering est une approche dans laquelle les organisations développent une plate-forme partagée (considérée comme un produit) pour améliorer l’expérience des développeurs et leur productivité dans toute l’organisation en fournissant des capacités en libre-service avec des opérations d’infrastructure automatisées en utilisant les techniques du DevOps.
Lorsqu’on introduit de nouveaux termes, cela donne toujours l’impression de concepts novateurs et disruptifs et que ce qui était fait avant n’était pas bon !
Les approches DevOps et agiles restent totalement valides mais c’est plutôt la manière de les amener et comment elles peuvent mieux fonctionner lorsqu’on passe à l’échelle.
Il s’agit ici d’avoir une approche plus optimale, mieux organisée et évolutive par rapport à l’utilisation classique du DevOps.
La démarche va se centrer sur les besoins des utilisateurs avec une approche produit en mode self-service mais appliquée à la plateforme.
Un nouveau terme avec des approches différentes implique souvent un nouvel intitulé de poste. C’est le cas ici avec le "Platform Engineer" qui pourrait avoir plusieurs rôles: Solutions Architect, DevOps Engineer, Site Reliability Engineer, System Engineer, Cloud Engineer, Platform Architect, Software Engineer, Infrastructure Engineer…
Nous pourrions dire que finalement le rôle principal serait de supprimer les obstacles entre le dev et la prod ! Et donc de parler de "developer enablers" ou d’“enablement teams.”
Chacun des points des sections suivantes ne sont pas spécialement novateurs, mais pris dans leur ensemble, ils constituent une approche nettement différeciante pour construire une démarche efficace, sécurisée et controlée de votre plateforme IT, en particulier d’un point de vue organisationnel et des flux de communication.
La chaîne de livraison, d’implémentation de la sécurité, de l’observabilité, la gestion des versions et des configurations, la construction d’infrastructures et tout autre étape nécessaire pour mettre en production un logiciel devient une charge de plus en plus conséquente et complexe pour respecter tous les standards nécessaires du marché.
Les équipes ont besoin de se refocaliser sur leur valeur et leur productivité et il y a plusieurs raisons à cette tendance.
La charge cognitive d’une équipe correspond à la capacité de stockage d’informations dans la mémoire de travail. Autrement dit, cela correspond à la quantité d’informations dont une équipe a besoin pour effectuer son travail.
Si cette capacité est dépassée, alors l’équipe se retrouvera en difficulté pour résoudre des problèmes, pour apprendre et pour avoir du recul sur l’efficacité de son travail.
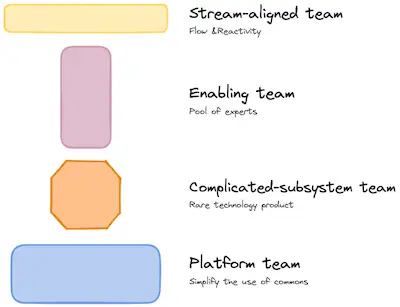
Avoir une organisation d’équipe spécifique en délimitant clairement les frontières et en rendant explicite les modes d’interactions entre les équipes, permet d’éviter cette surcharge et de favoriser la productivité du développement et de la livraison.
Les équipes en charge de développer et de délivrer un service ou un produit au client final, appelées « Stream-aligned Team », s’appuient donc sur d’autres équipes comme les « Platform teams » pour simplifier, accélérer, standardiser tout le flux de livraisons et pour libérer de la charge.
La réduction de la charge cognitive des équipes est un point clé d’amélioration dans les organisations
Pour en savoir plus sur ces notions, je vous suggère l’excellent livre « Team Topologies » de Matthew Skelton et Manuel Pais.
Les changements business, les besoins de nouvelles fonctionnalités, les innovations, les impacts du monde extérieur sur nos IT nécessitent d’avoir des flux de développement et de livraison de plus en plus rapide au travers de l’ensemble des équipes de l’entreprise.
Ces équipes doivent se concentrer sur les changements et les besoins business et donc éviter de réinventer la roue dans chaque équipe pour délivrer le logiciel.
Une plateforme doit permettre d’accélérer ces flux d’une manière standardisée.
Accélérer pour livrer plus vite des problèmes ou des bugs ne sert à rien. Les capacités de la plateforme doivent fournir un niveau de résilience et de fiabilité élevée avec un « design for failure » de façon à fournir une continuité de service très élevée (aussi bien d’un point de vue production que pour le développeur).
Cela s’applique sur l’ensemble des plateformes, pas seulement le runtime de production, mais aussi la chaîne de construction du logiciel, le flux de livraison, la plateforme d’observabilité, les différents environnements, les middlewares, la sécurité…
La fiabilité est le prérequis à la génération de feedback !
La notion de sécurité d’une plateforme doit être faite par design dès le début et inclure les principes de « Zero trust », « Shift left » et « Least principle privilege » sur l’ensemble de la chaîne.
Le partage de l’information est clé dans les différents environnements et sur les différentes plateformes en amenant une vue consolidée et claire du système applicatif avec une gouvernance et cela s’applique aussi à la sécurité.
Pour la plateforme ou pour les clients de celles-ci, il est important d’adopter une démarche d’ouverture vers une sécurité agissant en mode conseil et support plutôt que par contraintes.
La notion de risque ne se concentre pas seulement sur les aspects techniques, et par exemple il est courant que les procédures, les processus, la connaissance ne soient pas correctement documentés, voire pas du tout, et vivent entièrement dans la tête de certaines personnes clés de l’organisation. Cela rend la communication compliquée lorsque l’organisation grandit, ce qui contribue à la notion de "Bus factor" de vos équipes :
"C’est une mesure du risque dû à l’absence de partage d’informations et de compétences entre les membres d’une équipe. Le terme vient de la phrase « Combien de personnes clés dans votre équipe peuvent se faire renverser par un autobus avant que votre projet échoue ? »"
Construire une plateforme permet aussi de mutualiser, centraliser mais aussi de permettre d’optimiser les coûts. La gestion des coûts n’est pas simplement une question d’optimisation mais aussi une question de visibilité, de responsabilité et d’efficacité en amenant des techniques de :
La centralisation d’une plateforme permet d’amener cette culture FinOps qui réutilise les mêmes démarches que DevOps et du Platform Engineering :
L’expertise FinOps se construit par niveau de maturité (« Crawl, Walk, Run ») avec un changement qui s’opère dans le temps et qui nécessite d’avoir une approche globale pour en tirer tous les bénéfices et en particulier dans la phase de conception des applications et de la plateforme.
Le « Platform Engineering » est idéal pour mettre en place ces principes FinOps.
Pour l’instant, nous ne parlons pas encore beaucoup des approches GreenOps pour optimiser les émissions de carbone de nos applications et infrastructures, mais il est fortement probable que cela s’intègrera aussi dans les rôles de la plateforme.
C’est là qu’entre en jeu le Platform Engineering.
Cette équipe est en charge de gérer l’ensemble des outils et produits de la plateforme et d’amener une couche de standardisation au travers de l’ensemble des équipes, par exemple le choix des images de base par technologies, la manière d’utiliser kubernetes, le choix des solutions de CI/CD…
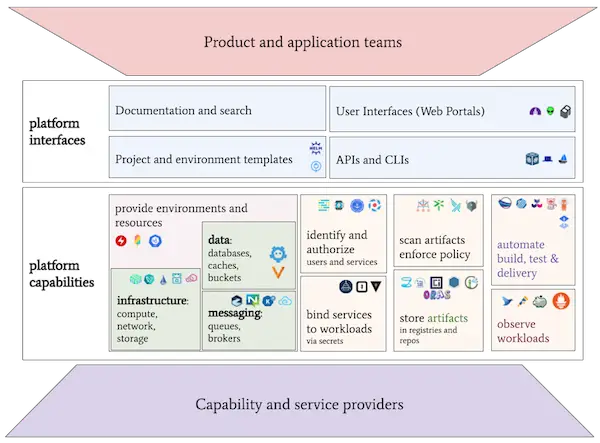
En résumé, le but est de s’occuper des besoins non-techniques des applications : VCS, CI/CD, runtime, système de provisionning, Le logging, le monitoring, les métriques, la sécurité, l’AD, le networking…
Et évidemment à chacun de ces besoins non-techniques correspond un ensemble d’outils ou de produits. Le CNCF landscape illustre bien la volumétrie et la combinaison de solutions :
Les « Platform Engineers » sélectionnent, standardisent, factorisent, configurent et administrent l’utilisation de ces outils et produits pour offrir un ensemble de services aux autres équipes.
Pour que cela fonctionne, les « Platform Engineers » ont la responsabilité totale des outils c’est-à-dire qu’ils sont administrateurs de l’ensemble et donnent des rôles de « User » aux équipes externes. C’est un rôle « Administrator » avec tout ce que cela comporte : mise en place (avec les meilleures pratiques), déploiement, patching, configuration, backup, sécurisation, monitoring, gestion des accès, gestion opérationnelle…
Cela correspond bien à 2 catégories de compétences différentes que l’on retrouvait avant au sein d’une équipe DevOps.
Avec cette approche, la charge de travail et la charge cognitive des équipes de dev sont largement réduites afin de laisser plus de capacité pour générer de la valeur business.
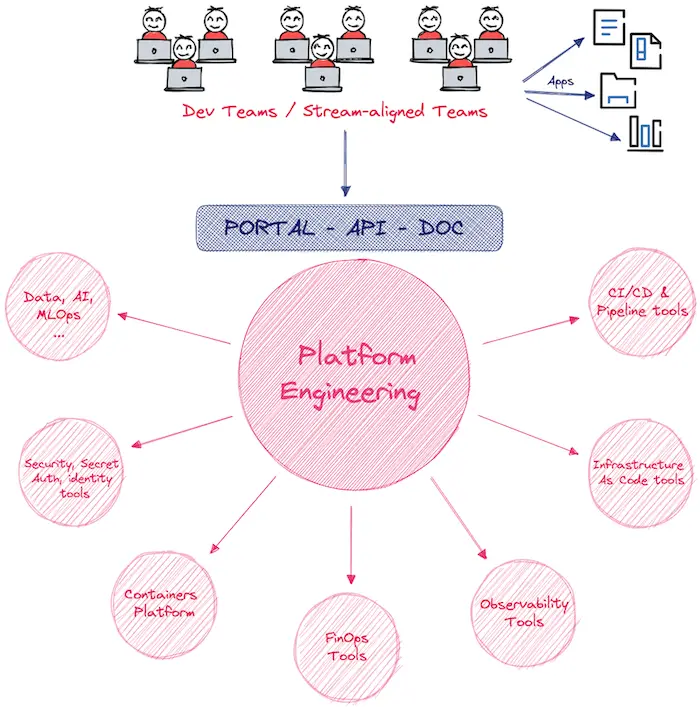
Est-ce suffisant ? Non, car sinon nous risquons de nous retrouver dans une situation avec des équipes silotées et de produire une plateforme qui ne sera pas adaptée au besoin du client : les développeurs.
Les platforms teams créent une couche d’abstraction par-dessus la plateforme avec une API et une User Interface (UI) simple, compréhensible et facile d’accès.
C’est ce que l’on appelle une IDP : Internal Developer Platform qui permettra d’interagir avec la plateforme et ainsi de provisionner l’ensemble des éléments nécessaires.
Nous sommes donc ici dans une approche de self-service avec un portail pour fournir un service comme le fait le PaaS (Platform as a Service) mais pour les développeurs internes et qui adresse un besoin business ciblé.
Le but est ici d’abstraire et de simplifier au maximum la complexité sous-jacente d’une telle plateforme tout en apportant de la flexibilité, de la sécurité et de la rapidité.
Tout comme la définition de contrat d’API pour les services applicatifs, l’IDP contribue à rendre explicites les relations inter-équipes en définissant clairement les services disponibles et la façon de les utiliser.
On pourrait penser que la standardisation des outils et produits par une équipe centralisée imposerait leurs choix : ArgoCD et pas Flux, GitlabCI et par CircleCI, Artifactory et pas Nexus, PostgressDB et pas MySQL … ce qui réduirait la flexibilité et la créativité des équipes.
L’équipe Platform Engineering ne souhaite surtout pas devenir un élément bloquant et générer des frustrations avec les autres équipes.
Au contraire ils doivent être au service des équipes de développement et travailler avec eux pour comprendre le besoin, les cas d’utilisations et intégrer ces nouveaux outils dans la plateforme, pour ensuite offrir ce service aux autres équipes.
La seule contrainte imposée, c’est de passer par la plateforme en laissant une flexibilité dans le choix des outils mais aussi sur la manière de les utiliser.
Cette plateforme est donc au service des équipes de développement en mettant l’accent sur la « Developer eXperience (DevX) ».
Il existe des situations où cela ne fait pas de sens d’intégrer un nouvel outil car trop spécifique et trop custom à une équipe. Dans ce cas, cette équipe pourra prendre la responsabilité de l’outil en accord avec l’équipe Platform Engineering.
Il est important des respecter les principes évoqués ici pour en tirer toute la puissance de cette approche au risque d’en avoir les effets inverses.
En particulier, il est important que les équipes puissent être autonomes sur l’utilisation de la plateforme et la manière dont elle doit être implémentée doit intégrer des limites et des gardes-fous.
Par exemple, l’utilisation de templates permet d’amener les « best practices » en termes d’usage et de configuration.
Que ce soit pour de l’Infra-As-Code (Terraform, Ansible, Pulumi, …), pour la CI et ses pipelines (GitLab, Github, CircleCI, Jenkins, …), pour la CD (Helm, ArgoCD, Flux, …), il existe à chaque fois un système de template permettant de factoriser, d’homogénéiser et de mettre les règles d’architecture, de compliance et de sécurité tout en amenant un bon niveau de flexibilité.
Le but est clairement d’amener de la consistance des usages au travers de l’organisation et d’enlever de la charge aux autres équipes et en particulier celle de dev que l’on appelle les Stream-aligned Teams
Lorsque l’on commence cette démarche, il faut éviter de faire un master plan hyper générique qui englobe tous les use cases.
Il faut commencer avec une approche agile en déterminant un MVP (Minimum Viable Product) et itérer par petits incréments, le but étant d’avoir un feedback rapide pour ajuster le besoin, les priorités et la direction.
Il faut identifier la cible idéale par rapport au contexte des équipes et de l’entreprise puis aller dans cette direction de manière progressive aussi bien pour ceux qui l’implémentent que pour ceux qui devront migrer dessus.
Un point essentiel pour l’implémentation de cette IDP c’est de la traiter comme un produit et non comme un projet classique qui se termine et passe en mode maintenance.
Nous sommes avec une approche Platform-as-a-Service qui nécessite un développement et une amélioration continue. Et ce développement est assuré par les équipes Platform Engineers qui sont donc responsables d’amener le changement (nouvelles fonctionnalités, bug fixes, améliorations, mise à jour des services et produits) pour les développeurs internes de l’entreprise. D’où le nom IDP : Internal Developper Platform.
Et puisque l’on parle de produit, cela signifie aussi avoir un versionning associé, un release management, une visibilité (Release, Roadmap, …), une documentation, une API claire.
Cela se fait en fonction des besoins des équipes internes pour comprendre leurs priorités, ce qui les bloquent, les défis qu’ils ont besoin de relever.
L’observabilité de votre produit est essentielle pour mesurer l’apport de chaque version et valider que ce qui est mis en place est bien aligné avec l’utilisation envisagée.
Pour construite cette approche produit de la plateforme et la faire évoluer correctement tout comme on le ferait avec un produit applicatif classique, il faut :
Typiquement, une équipe plateforme va travailler en étroite collaboration avec une équipe de développement pour améliorer la plateforme sur un sujet dont l’équipe de développement a besoin.
Si l’on considère que ce besoin fait du sens pour les équipes, alors à l’issue de la collaboration, l’équipe plateforme passe dans un mode "As-a-Service" de la fonctionnalité en la mettant à disposition de toutes les équipes de développement.
Au travers de cette démarche, on comprend rapidement que les topologies et les structures d’équipes sont essentielles au succès de ce type de plateforme.
L’objectif est de délivrer de la valeur pour les clients (internes et externes) et non de se focaliser sur les aspects techniques.
Cela signifie que différentes organisations peuvent avoir besoin de structures d’équipe différentes pour qu’une collaboration entre les différents acteurs soit efficace.
Le site devopstopologies définit des patterns et des anti-patterns (ou "anti-types") orientés sur le DevOps.
Remember: "There is no ‘right’ team topology, but several ‘bad’ topologies for any one organisation."
Ce type de plateformes a un impact mesurable sur la productivité et la performance de l’organisation. Il est donc important de la mesurer pour l’équipe, les clients et l’entreprise.
On ne peut pas améliorer ce que l’on ne mesure pas !
Pour la mesurer, on utilisera classiquement les indicateurs DevOps (voir l’étude DORA), tels que :
Mais si l’on s’arrêtait à ce niveau, il nous manquerait la vision des utilisateurs !
Ainsi un indicateur « NPS » (Net Promoter Score) permet d’évaluer la satisfaction clients et ainsi de mettre en avant la « Developer eXperience » par rapport à la plateforme.
Tout comme un produit classique, il s’agit bien de maximiser la satisfaction de ses utilisateurs, les développeurs.
Finalement, avec les critères énoncés précédemment : Approche produit, DevX, Visibilité, API, Release, Documentation, contrats clairs… nous pourrions parler de Plateforme open-source pour l’entreprise.
Par exemple, la CNCF rend complètement transparent le code, l’architecture, l’organisation, la gouvernance… de ces projets :
Cette démarche Open-source est saine, rend très explicite le fonctionnement global, simplifie les communications, facilite l’amélioration et permet de créer une plateforme pérenne.
En résumé, il y a une responsabilité partagée : l’équipe plateforme est responsable au niveau opérationnel tandis que les équipes applicatives sont responsables de l’utilisation des outils et de leur intégration dans le cycle de vie des applications.
Les équipes de développement métier ont donc encore besoin de savoir comment déployer leurs applications dans un cluster kubernetes par exemple ou comment utiliser les modules Terraform pour influencer leur infrastructure ou encore comment utiliser les templates Gitlab CI pour les customiser en fonction des besoins.
La nécessité d’exigences non fonctionnelles reste toujours valide même si le périmètre est largement réduit par ce qu’amène l’IDP. Et donc le besoin d’ingénieur DevOps au sein des équipes reste tout à fait pertinent mais en s’appuyant sur la plateforme.
A noter qu’il est tout à fait possible que les DevOps contribuent à la plateforme, comme on le ferait dans une démarche produit open-source.
Ce qui devient encore plus intéressant, puisque l’on traite la plateforme comme un produit, c’est de s’appliquer les mêmes approches (« Eat your own dog food ») et donc d’avoir une approche DevOps sur la plateforme elle-même, ce qui nécessite d’avoir des DevOps Engineers dans les équipes applicatives que l’on appelle donc les « Platform Engineers ».
Pour construire une telle plateforme, les outils et produits utilisés sont évidemment les mêmes que pour DevOps.
Typiquement et de manière non exhaustive, nous retrouvons ce type d’outils « DevOps » qui permettront de construire la plateforme :

Mais aussi des nouveaux outils orientés catalogue de services centralisés permettant d’avoir un framework ou de construire un portail développeur :

Vous pourriez décider de faire votre propre framework et votre portail, mais avant de se lancer dans ce type d’approche, il est important d’évaluer les fonctionnalités souhaitées (en réfléchissant dans un horizon de temps moyens ou longs termes) et de déterminer si les produits (open source ou non) existants du marché permettent facilement de le faire.
A l’inverse, l’utilisation d’un outil ou d’un produit doit se faire sans créer de la « sur-customisation ». Il est important d’utiliser un produit pour ce qu’il sait faire et de ne pas payer le prix, quelques années plus tard, de la personnalisation à outrance.
Le Platform Engineering n’est pas du tout un remplacement au DevOps, mais s’inscrit plutôt dans une continuité où la collaboration des DevOps Engineers avec les Platform Engineers est essentielle pour créer une plateforme centralisée en mode self-service répondant aux besoins des équipes de développement.
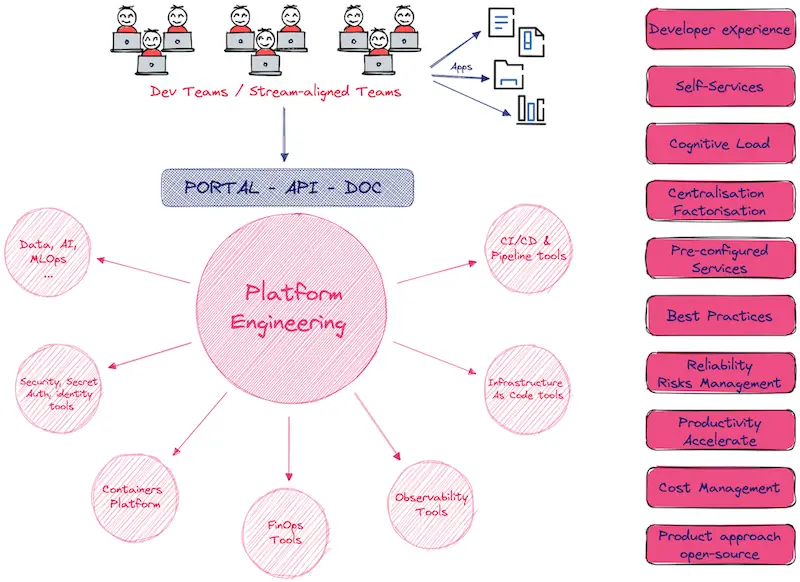
Les capacités de ce type de plateforme sont de plusieurs natures et fournissent plusieurs services et fonctionnalités qui pourraient se résumer par le schéma suivant de la CNCF :
Gardez à l’esprit que, comme le platform engineering est un terme relativement nouveau, il y a encore une certaine marge de manœuvre quant à sa définition. L’industrie est encore en train de déterminer comment cela va réellement évoluer. Une chose est sûre : le rôle que joue l’automatisation et l’efficacité dans le processus de développement logiciel ne feront que gagner en importance.
Comme le montre cet article du Gartner : Top Strategic Technology Trends for 2023: Platform Engineering, à mesure que les systèmes cloud distribués deviennent plus couramment utilisés et que les modèles architecturaux continuent d’évoluer, la demande d’ingénieurs de plate-forme et de portails de développement internes devrait augmenter.
Il existe beaucoup de cas d’utilisations différents et d’organisations possibles en fonction des contextes pour créer une plateforme. Cet article avait pour but de donner assez d’éléments pour implémenter une vision Platform-as-a-Product qui vous permettra de passer à l’échelle votre IT.