
Par Maxime Ancellin.
In my previous post, I introduced you to dependency management tools, with a particular focus on Renovate.
Now, we are going to explore how to manage our infrastructure and its applications just like any other application dependencies.
This will allow us to easily automate deployments and keep our technical stack up to date.
Everything will be done through a GitOps process.
If you’re not familiar with this term, I encourage you to read our dedicated post on the topic: GitOps and the Millefeuille dilemma.
This post is a follow-up to the article “Automated Dependency Management“, so I recommend reading that one first.
The approach described below applies primarily to a small-scale environment, such as that of a start-up or scale-up.
This type of context is characterized by a streamlined organization, with very few intermediaries and team members who often take on cross-functional responsibilities.
The entire technical chain is managed by a handful of people, which makes governance easier.
This approach differs from that of a more structured company, where specialized teams have clearly defined responsibilities within specific scopes.
To explore a complementary perspective, you can read the following article: Promoting Changes and Releases with GitOps.
Our technical infrastructures have evolved significantly in recent years with the concepts of microservices and cloud-native applications.
This means that managing large sets of up-to-date applications is essential to ensure the proper functioning of systems as well as their security.
Here are a few key fundamentals for what follows.
I won’t go into too much detail here, but let’s describe the characteristics of this type of application so that we’re aligned for the rest of this article.
To adhere to these key principles, it’s common practice to have a separate Git project for each service.
This significantly complicates application management due to the large number of services.
To address the challenges of managing a growing number of applications, we’ve aimed to automate as many repetitive update tasks as possible for the tools we use.
This topic was covered in my last post.
But now, the question arises on how to manage these applications within our infrastructure, making the infrastructure itself a kind of dependency.
Indeed, our applications are versioned and autonomous.
For many modern systems, these applications include within their Git projects the creation of their containers, and even their deployment configurations.
This allows us to have, within the same project, the versions and all the resources that make our application “ready to deploy.”
In our project, we add a deployments folder, which contains the following configurations:
├── charts # Fichier de références pour Helm
│ ├── Chart.yaml
│ ├── default.yaml
│ ├── staging.yaml
│ ├── pre-production.yaml
│ └── production.yaml
└── configurations # Manifests Kubernetes
├── staging
│ └── secrets
│ ├── my-secret-a-sealed.yaml
│ └── my-secret-b-sealed.yaml
├── pre-production
│ └── secrets
│ ├── my-secret-a-sealed.yaml
│ └── my-secret-b-sealed.yaml
└── production
└── secrets
├── my-secret-a-sealed.yaml
└── my-secret-b-sealed.yamlFirst and foremost, if you are not familiar with this term, I encourage you to read our dedicated article on the subject: GitOps and the Millefeuille dilemma.
Now, we will explore how it is possible to manage our infrastructure and its applications like any other application dependencies.
For this, we will need a repository for our Git/application projects.
This will allow us several things:
This repository is useful, but it does not solve our environmental issue.
To manage multiple environments, we will create one for each of them.
For example, I could create a Helm chart that will allow me to deploy a list of applications (depending on your existing GitOps chain).
applications:
- name: frontend
sources:
- repoURL: git@github.com:my-org/frontend.git
targetRevision: 1.2.3
- name: api
sources:
- repoURL: git@github.com:my-org/api.git
targetRevision: 5.4.3Regardless of the format we choose, Renovate will be able, through a custom manager of type regex, to find the dependency as well as the version.
In our case, we can use the configuration below:
renovate.json
{
"$schema": "https://docs.renovatebot.com/renovate-schema.json",
"separateMajorMinor": false,
"customManagers": [
{
"customType": "regex",
"fileMatch": [
"staging.yaml"
],
"matchStrings": [
"repoURL: (?<depName>.*?)n(( |n)*)targetRevision: (?<currentValue>.*)"
],
"datasourceTemplate": "git-tags"
},
],
"packageRules": [
{
"matchManagers": [
"custom.regex"
],
"matchFileNames": [
"staging.yaml"
],
"groupName": "release-to-staging",
"reviewers": [
"team:qa",
]
},
]
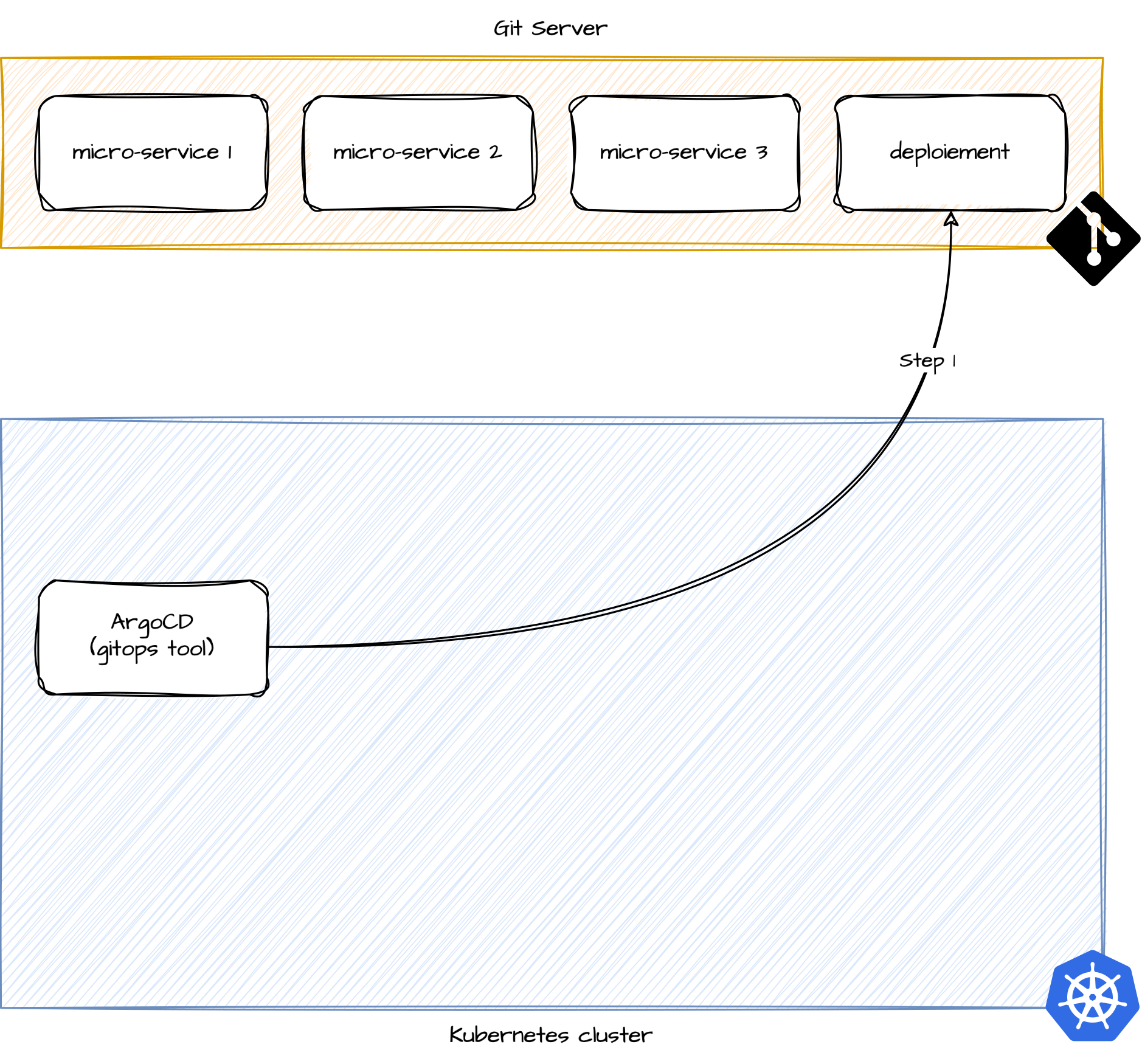
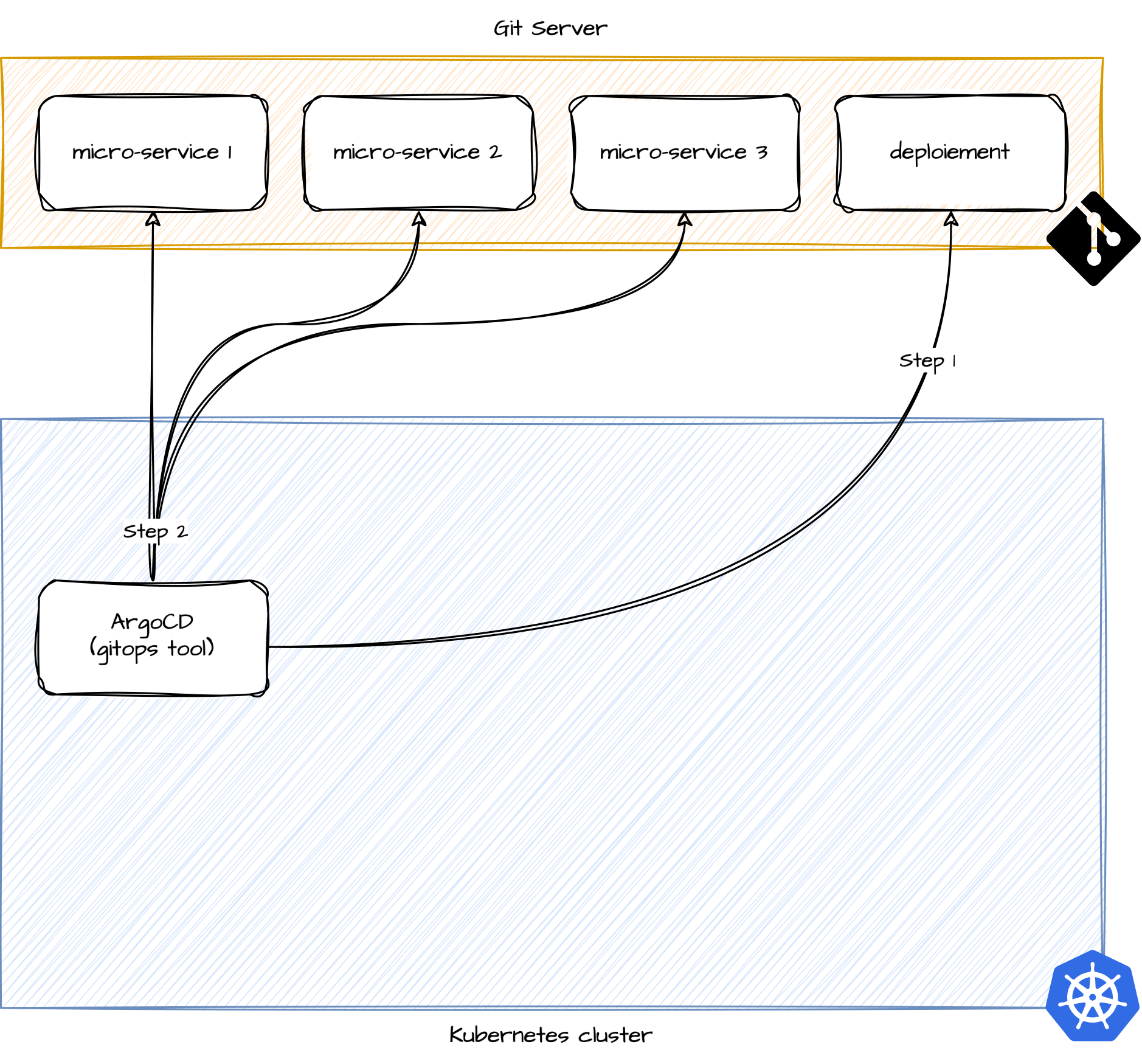
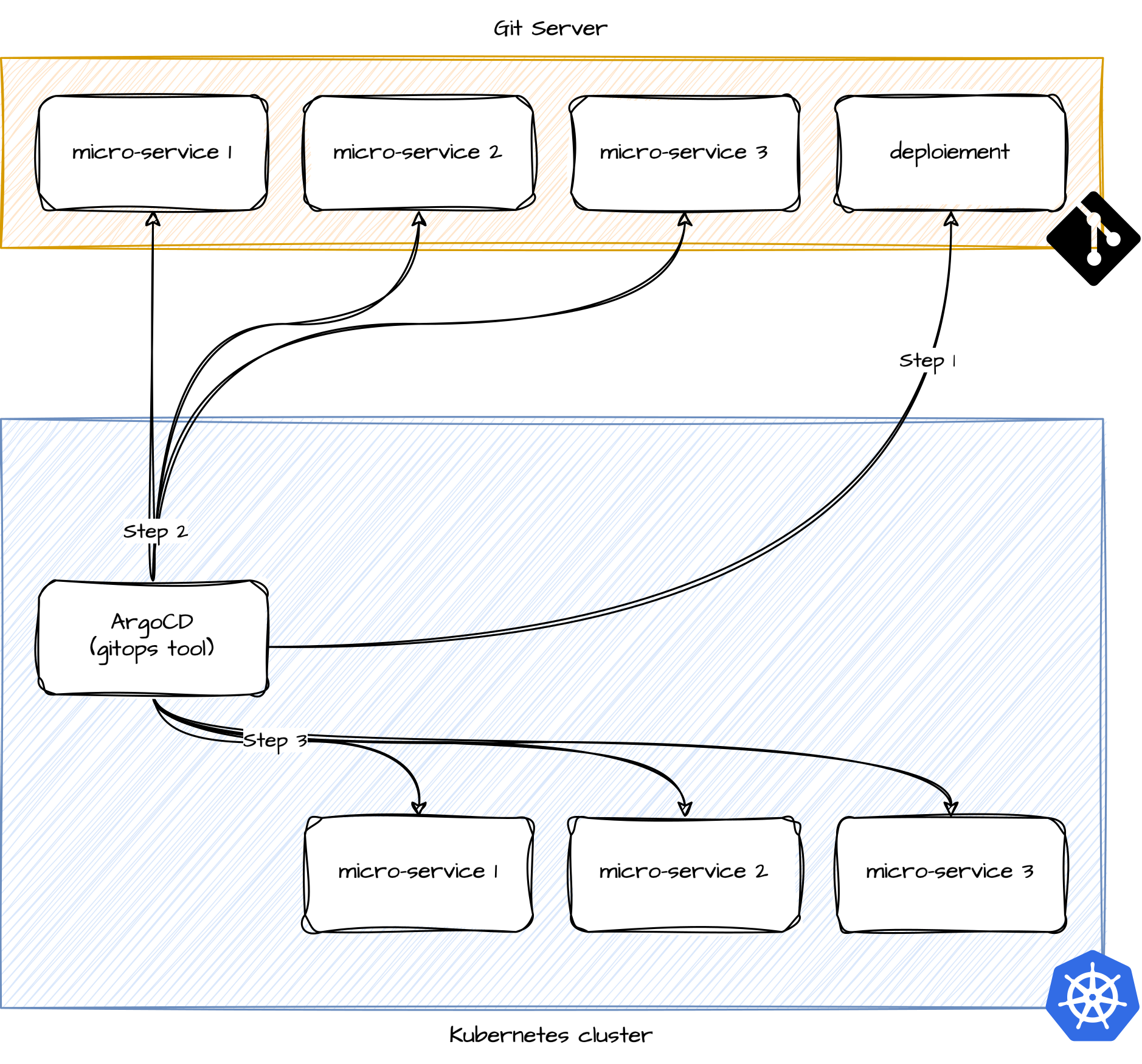
}We need to have an operation similar to that described by the diagrams below:
Reading the file referencing our applications
Reading the application Git projects
Deploying the applications
Now that we have our repository and Renovate is capable of interpreting it, we will see how it is possible to automatically manage updates and thus deployments.
We have seen that it is relatively easy to automatically manage dependency updates in a file, even with a custom format.
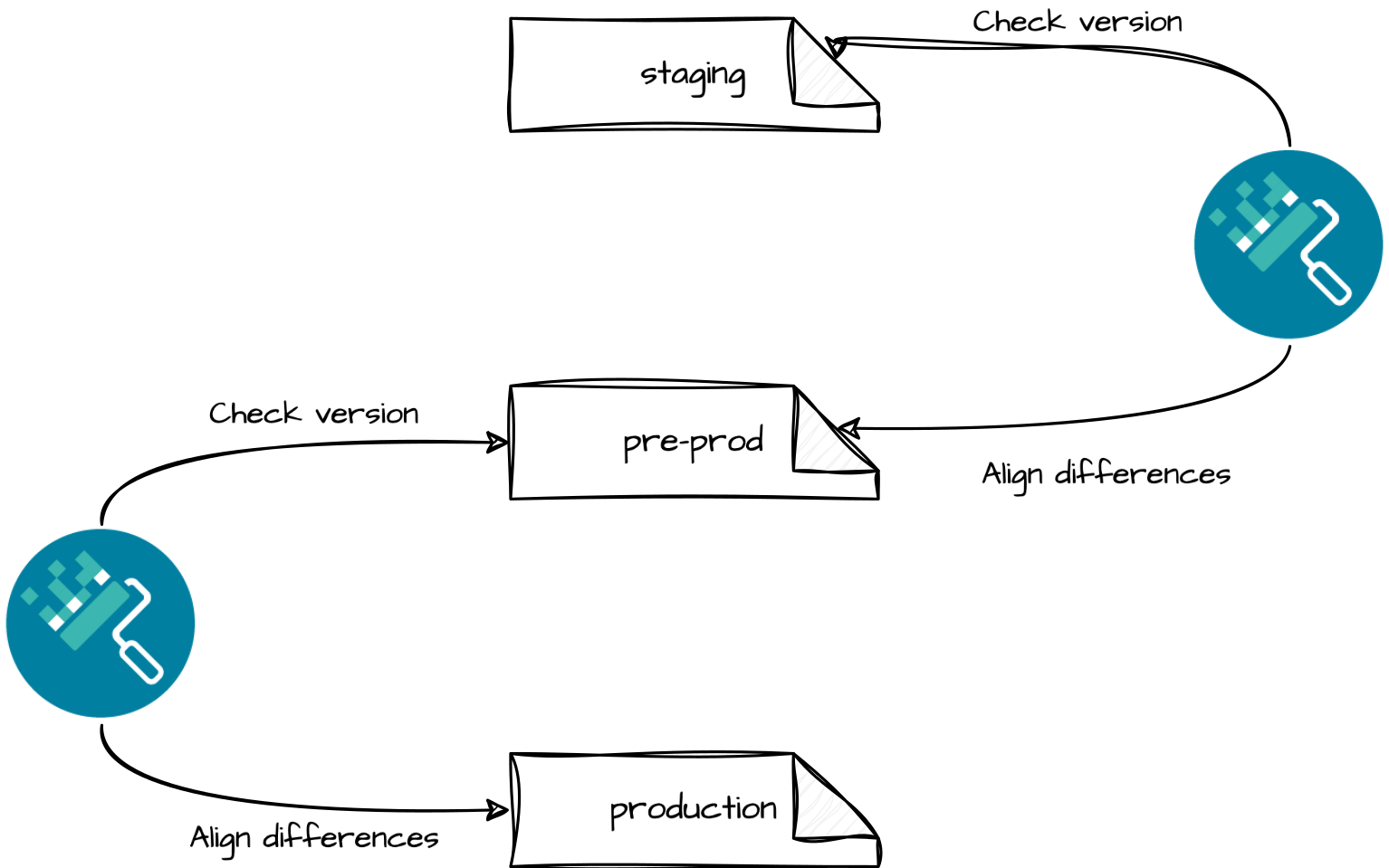
Now, we need to manage the promotion between environments to avoid having all our environments being offered the same updates at the same time, without respecting the promotion process between environments.
If we take our environment file from the previous section and assume that we have the following environments, each with its own rules:
The representation of the flow between the environments will therefore be as follows:
From a Renovate configuration perspective, we will need to set up the following configuration:
{
"customDatasources": {
"localstaging": {
"format": "yaml",
"defaultRegistryUrlTemplate": "file://applications/staging.yaml",
"transformTemplates": [
"{"releases":[{"version": 'applications'.applications.sources[repoURL='{{depName}}'].targetRevision }]}"
]
},
"localpreprod": {
"format": "yaml",
"defaultRegistryUrlTemplate": "file://applications/preprod.yaml",
"transformTemplates": [
"{"releases":[{"version": 'applications'.applications.sources[repoURL='{{depName}}'].targetRevision }]}"
]
}
},
"customManagers": [
{
"customType": "regex",
"fileMatch": [
"applications/staging.yaml"
],
"matchStrings": [
"repoURL: (?<depName>.*?)\n(( |\n)*)targetRevision: (?<currentValue>.*)"
],
"datasourceTemplate": "git-tags"
},
{
"customType": "regex",
"fileMatch": [
"applications/preprod.yaml"
],
"matchStrings": [
"repoURL: (?<depName>.*?)\n(( |\n)*)targetRevision: (?<currentValue>.*)"
],
"datasourceTemplate": "custom.localstaging"
},
{
"customType": "regex",
"fileMatch": [
"applications/prod.yaml"
],
"matchStrings": [
"repoURL: (?<depName>.*?)\n(( |\n)*)targetRevision: (?<currentValue>.*)"
],
"depNameTemplate": "{{{ replace 'git@github.com:my-org/(.*).git' '$1' depName }}}",
"datasourceTemplate": "custom.localpreprod"
}
],
"packageRules": [
{
"matchManagers": [
"custom.regex"
],
"matchFileNames": [
"staging.yaml"
],
"groupName": "staging",
"automerge": true
},
{
"matchManagers": [
"custom.regex"
],
"matchFileNames": [
"preprod.yaml"
],
"groupName": "pre-production",
"reviewers": [
"team:qa"
]
},
{
"matchManagers": [
"custom.regex"
],
"matchFileNames": [
"prod.yaml"
],
"groupName": "production",
"reviewers": [
"team:leader"
]
}
]
}We now have a new concept that has emerged: the notion of customDatasources.
A custom datasource is defined for each environment sourcing a YAML file:
preprod.yaml.prod.yaml.Each datasource is configured to read the corresponding YAML file and extract the version (targetRevision) of an application using the transformTemplates instruction.
We do not use this for the staging environment because we directly utilize the
git-tagsprovided by Renovate.
In general, we all love automation because it saves us from time-consuming tasks that provide little value.
But it’s always interesting to look further.
With the proposal above, we can avoid all human errors regarding the versions that will be deployed in the environments.
The fact that this process goes through “pull requests” and that we manage it using GitOps allows us to have perfect traceability of the actions performed.
Moreover, we reinforce the promotion process between environments because the tool relies solely on the lower environment to source the new versions to deploy.
You also have the option to choose the cadence of Renovate to precisely define your deployment rhythm.
Without this, your only limit will be the speed at which you iterate and merge changes.
Note: To achieve such a dynamic, it is important that you have automated the rest of the process.
Otherwise, you will quickly find yourself blocked at certain stages, which will create frustration and annoyance around the blocking elements.
Obviously, this kind of automation can disrupt many of your habits but also brings numerous advantages.
To minimize friction and facilitate adoption, here are some tips.
It is important to align your architecture with your organizational structure.
This means that your GitOps source architecture should perfectly correspond to your teams, and the configured permissions should reflect your hierarchy.
The risk of not doing this is that no one will be available or able to easily authorize the proposed deployments.
This is generally related to GitOps, but Renovate can highlight shortcomings when implementing this.
To have better visibility on the proposed “pull requests,” I highly recommend maintaining an up-to-date changelog.md file in your Git repository.
This will allow Renovate to include it in its proposals, giving you all the information at a glance.
If you don’t have time to do this, there are many tools (Git-chglog, Conventional-changelog) available that can automate the process.
Automation does not mean losing control.
It allows you to save time on time-consuming tasks and focus solely on what matters.
This is what Renovate enables us to do in our case.
It takes care of finding the updates to be made for each of our environments while proposing them for our validation.
You can also work with packageRules to set up notifications for the people involved in the proposed “pull request.”
As you can understand from these two articles on Renovate, trying it is adopting it.
Once implemented, it will be difficult to go back.
In reality, it requires relatively little effort but will provide you with significant time savings and efficiency.
Moreover, you can integrate it at several levels:
All of this can be enhanced through a GitOps approach.
We explored how this approach allows for effectively structuring updates across different environments while ensuring total control through “pull requests” and respecting the promotion processes.
Adopting this method not only helps reduce human errors but also streamlines your deployments while maintaining complete traceability at every stage.
It’s a powerful and cost-effective solution to optimize your continuous delivery pipelines while staying aligned with GitOps principles.
Nevertheless, before implementing this, consider adapting your approach to fit your organization.
In our example, this was done in the context of a small-to-medium-sized company, such as a startup or scale-up.
Now it’s your turn to deploy with just one click!